1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
# Benchmarks for sdsl data structures
This directory contains a set of benchmarks for [sdsl][sdsl]
data structures. Each benchmark is in its own subdirectory and
so far we have:
* [indexing_count](./indexing_count): Evaluates the performance
of count queries on different FM-Indexes/CSAs. Count query
means _How many times occurs my pattern P in the text T?_
* [indexing_extract](./indexing_extract): Evaluates the performance
of extracting continues sequences of text out of FM-Indexes/CSAs.
* [indexing_locate](./indexing_locate): Evaluates the performance
of _locate queries_ on different FM-Indexes/CSAs. Locate query
means _At which positions does pattern P occure in T?_
* [rrr_vector](./rrr_vector): Evaluates the performance of
the 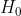-compressed
bitvector [rrr_vector](../include/sdsl/rrr_vector.hpp).
Operations `access`, `rank`, and `select` are benchmarked on
different inputs.
* [wavelet_trees](./wavelet_trees): Evaluates the performance of wavelet trees.
You can executed the benchmarks by calling `make timing`
in the specific subdirectory.
Test inputs will be automatically generated or downloaded
from internet sources, such as the excellent [Pizza&Chili][pz]
website, and stored in the [data](./data) directory.
Directory [tmp](./tmp) is used to store temporary files (like
plain suffix arrays) which are used to generate compressed
structures.
## Prerequisites
The following tools, which are available as packages for Mac OS X and
most Linux distributions, are required:
* [cURL][CURL] is required by the test input download script.
* [gzip][GZIP] is required to extract compressed files.
## Literature
The benchmark code originates from the following article and can be used
to easily reproduce the results presented in the paper.
Simon Gog, Matthias Petri: _Optimized Succinct Data Structures for Massive Data_. 2013.
Accepted for publication in Software, Practice and Experience.
[Preprint][PP]
## Author
Simon Gog (simon.gog@gmail.com)
[sdsl]: https://github.com/simongog/sdsl "sdsl"
[pz]: http://pizzachili.di.unipi.it "Pizza&Chili"
[PP]: http://people.eng.unimelb.edu.au/sgog/optimized.pdf "Preprint"
[CURL]: http://curl.haxx.se/ "cURL"
[GZIP]: http://www.gnu.org/software/gzip/ "Gzip Compressor"
|
