1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
|
[](https://travis-ci.com/postgrespro/rum)
[](https://badge.fury.io/pg/rum)
[](https://raw.githubusercontent.com/postgrespro/rum/master/LICENSE)
[](https://postgrespro.com/)
# RUM - RUM access method
## Introduction
The **rum** module provides an access method to work with a `RUM` index. It is based
on the `GIN` access method's code.
A `GIN` index allows performing fast full-text search using `tsvector` and
`tsquery` types. But full-text search with a GIN index has several problems:
- Slow ranking. It needs positional information about lexemes to do ranking. A `GIN`
index doesn't store positions of lexemes. So after index scanning, we need an
additional heap scan to retrieve lexeme positions.
- Slow phrase search with a `GIN` index. This problem relates to the previous
problem. It needs positional information to perform phrase search.
- Slow ordering by timestamp. A `GIN` index can't store some related information
in the index with lexemes. So it is necessary to perform an additional heap scan.
`RUM` solves these problems by storing additional information in a posting tree.
For example, positional information of lexemes or timestamps. You can get an
idea of `RUM` with the following diagram:
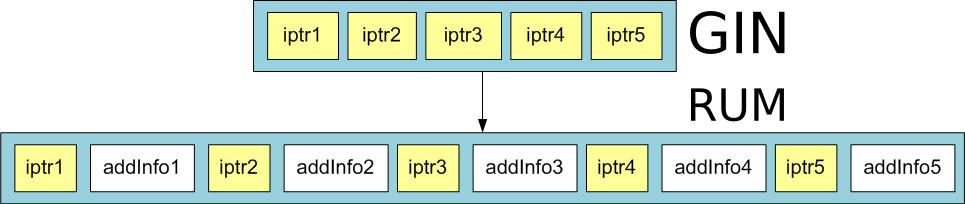
A drawback of `RUM` is that it has slower build and insert times than `GIN`.
This is because we need to store additional information besides keys and because
`RUM` uses generic Write-Ahead Log (WAL) records.
## License
This module is available under the [license](LICENSE) similar to
[PostgreSQL](http://www.postgresql.org/about/licence/).
## Installation
Before building and installing **rum**, you should ensure following are installed:
* PostgreSQL version is 9.6+.
Typical installation procedure may look like this:
### Using GitHub repository
$ git clone https://github.com/postgrespro/rum
$ cd rum
$ make USE_PGXS=1
$ make USE_PGXS=1 install
$ make USE_PGXS=1 installcheck
$ psql DB -c "CREATE EXTENSION rum;"
### Using PGXN
$ USE_PGXS=1 pgxn install rum
> **Important:** Don't forget to set the `PG_CONFIG` variable in case you want to test `RUM` on a custom build of PostgreSQL. Read more [here](https://wiki.postgresql.org/wiki/Building_and_Installing_PostgreSQL_Extension_Modules).
## Common operators and functions
The **rum** module provides next operators.
| Operator | Returns | Description
| -------------------- | ------- | ----------------------------------------------
| tsvector <=> tsquery | float4 | Returns distance between tsvector and tsquery.
| timestamp <=> timestamp | float8 | Returns distance between two timestamps.
| timestamp <=| timestamp | float8 | Returns distance only for left timestamps.
| timestamp |=> timestamp | float8 | Returns distance only for right timestamps.
The last three operations also work for types timestamptz, int2, int4, int8, float4, float8,
money and oid.
## Operator classes
**rum** provides the following operator classes.
### rum_tsvector_ops
For type: `tsvector`
This operator class stores `tsvector` lexemes with positional information. It supports
ordering by the `<=>` operator and prefix search. See the example below.
Let us assume we have the table:
```sql
CREATE TABLE test_rum(t text, a tsvector);
CREATE TRIGGER tsvectorupdate
BEFORE UPDATE OR INSERT ON test_rum
FOR EACH ROW EXECUTE PROCEDURE tsvector_update_trigger('a', 'pg_catalog.english', 't');
INSERT INTO test_rum(t) VALUES ('The situation is most beautiful');
INSERT INTO test_rum(t) VALUES ('It is a beautiful');
INSERT INTO test_rum(t) VALUES ('It looks like a beautiful place');
```
To create the **rum** index we need create an extension:
```sql
CREATE EXTENSION rum;
```
Then we can create new index:
```sql
CREATE INDEX rumidx ON test_rum USING rum (a rum_tsvector_ops);
```
And we can execute the following queries:
```sql
SELECT t, a <=> to_tsquery('english', 'beautiful | place') AS rank
FROM test_rum
WHERE a @@ to_tsquery('english', 'beautiful | place')
ORDER BY a <=> to_tsquery('english', 'beautiful | place');
t | rank
---------------------------------+---------
It looks like a beautiful place | 8.22467
The situation is most beautiful | 16.4493
It is a beautiful | 16.4493
(3 rows)
SELECT t, a <=> to_tsquery('english', 'place | situation') AS rank
FROM test_rum
WHERE a @@ to_tsquery('english', 'place | situation')
ORDER BY a <=> to_tsquery('english', 'place | situation');
t | rank
---------------------------------+---------
The situation is most beautiful | 16.4493
It looks like a beautiful place | 16.4493
(2 rows)
```
### rum_tsvector_hash_ops
For type: `tsvector`
This operator class stores a hash of `tsvector` lexemes with positional information.
It supports ordering by the `<=>` operator. It **doesn't** support prefix search.
### rum_TYPE_ops
For types: int2, int4, int8, float4, float8, money, oid, time, timetz, date,
interval, macaddr, inet, cidr, text, varchar, char, bytea, bit, varbit,
numeric, timestamp, timestamptz
Supported operations: `<`, `<=`, `=`, `>=`, `>` for all types and
`<=>`, `<=|` and `|=>` for int2, int4, int8, float4, float8, money, oid,
timestamp and timestamptz types.
This operator supports ordering by the `<=>`, `<=|` and `|=>` operators. It can be used with
`rum_tsvector_addon_ops`, `rum_tsvector_hash_addon_ops' and `rum_anyarray_addon_ops` operator classes.
### rum_tsvector_addon_ops
For type: `tsvector`
This operator class stores `tsvector` lexemes with any supported by module
field. See the example below.
Let us assume we have the table:
```sql
CREATE TABLE tsts (id int, t tsvector, d timestamp);
\copy tsts from 'rum/data/tsts.data'
CREATE INDEX tsts_idx ON tsts USING rum (t rum_tsvector_addon_ops, d)
WITH (attach = 'd', to = 't');
```
Now we can execute the following queries:
```sql
EXPLAIN (costs off)
SELECT id, d, d <=> '2016-05-16 14:21:25' FROM tsts WHERE t @@ 'wr&qh' ORDER BY d <=> '2016-05-16 14:21:25' LIMIT 5;
QUERY PLAN
-----------------------------------------------------------------------------------
Limit
-> Index Scan using tsts_idx on tsts
Index Cond: (t @@ '''wr'' & ''qh'''::tsquery)
Order By: (d <=> 'Mon May 16 14:21:25 2016'::timestamp without time zone)
(4 rows)
SELECT id, d, d <=> '2016-05-16 14:21:25' FROM tsts WHERE t @@ 'wr&qh' ORDER BY d <=> '2016-05-16 14:21:25' LIMIT 5;
id | d | ?column?
-----+---------------------------------+---------------
355 | Mon May 16 14:21:22.326724 2016 | 2.673276
354 | Mon May 16 13:21:22.326724 2016 | 3602.673276
371 | Tue May 17 06:21:22.326724 2016 | 57597.326724
406 | Wed May 18 17:21:22.326724 2016 | 183597.326724
415 | Thu May 19 02:21:22.326724 2016 | 215997.326724
(5 rows)
```
> **Warning:** Currently RUM has bogus behaviour when one creates an index using ordering over pass-by-reference additional information. This is due to the fact that posting trees have fixed length right bound and fixed length non-leaf posting items. It isn't allowed to create such indexes.
### rum_tsvector_hash_addon_ops
For type: `tsvector`
This operator class stores a hash of `tsvector` lexemes with any supported by module
field.
It **doesn't** support prefix search.
### rum_tsquery_ops
For type: `tsquery`
It stores branches of query tree in additional information. For example, we have the table:
```sql
CREATE TABLE query (q tsquery, tag text);
INSERT INTO query VALUES ('supernova & star', 'sn'),
('black', 'color'),
('big & bang & black & hole', 'bang'),
('spiral & galaxy', 'shape'),
('black & hole', 'color');
CREATE INDEX query_idx ON query USING rum(q);
```
Now we can execute the following fast query:
```sql
SELECT * FROM query
WHERE to_tsvector('black holes never exists before we think about them') @@ q;
q | tag
------------------+-------
'black' | color
'black' & 'hole' | color
(2 rows)
```
### rum_anyarray_ops
For type: `anyarray`
This operator class stores `anyarray` elements with length of the array.
It supports operators `&&`, `@>`, `<@`, `=`, `%` operators. It also supports ordering by `<=>` operator.
For example, we have the table:
```sql
CREATE TABLE test_array (i int2[]);
INSERT INTO test_array VALUES ('{}'), ('{0}'), ('{1,2,3,4}'), ('{1,2,3}'), ('{1,2}'), ('{1}');
CREATE INDEX idx_array ON test_array USING rum (i rum_anyarray_ops);
```
Now we can execute the query using index scan:
```sql
SET enable_seqscan TO off;
EXPLAIN (COSTS OFF) SELECT * FROM test_array WHERE i && '{1}' ORDER BY i <=> '{1}' ASC;
QUERY PLAN
------------------------------------------
Index Scan using idx_array on test_array
Index Cond: (i && '{1}'::smallint[])
Order By: (i <=> '{1}'::smallint[])
(3 rows
SELECT * FROM test_array WHERE i && '{1}' ORDER BY i <=> '{1}' ASC;
i
-----------
{1}
{1,2}
{1,2,3}
{1,2,3,4}
(4 rows)
```
### rum_anyarray_addon_ops
For type: `anyarray`
This operator class stores `anyarray` elements with any supported by module
field.
## Todo
- Allow multiple additional information (lexemes positions + timestamp).
- Improve ranking function to support TF/IDF.
- Improve insert time.
- Improve GENERIC WAL to support shift (PostgreSQL core changes).
## Authors
Alexander Korotkov <a.korotkov@postgrespro.ru> Postgres Professional Ltd., Russia
Oleg Bartunov <o.bartunov@postgrespro.ru> Postgres Professional Ltd., Russia
Teodor Sigaev <teodor@postgrespro.ru> Postgres Professional Ltd., Russia
Arthur Zakirov <a.zakirov@postgrespro.ru> Postgres Professional Ltd., Russia
Pavel Borisov <p.borisov@postgrespro.com> Postgres Professional Ltd., Russia
Maxim Orlov <m.orlov@postgrespro.ru> Postgres Professional Ltd., Russia
|
