1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
764
765
766
767
768
769
770
771
772
773
774
775
776
777
778
779
780
781
782
783
784
785
786
787
788
789
790
791
792
793
794
795
796
797
798
799
800
801
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
869
870
871
872
873
874
875
876
877
878
879
880
881
882
883
884
885
886
887
888
889
890
891
892
893
894
895
896
897
898
899
900
901
902
903
904
905
906
907
908
909
910
911
912
913
914
915
916
917
918
919
920
921
922
923
924
925
926
927
928
929
930
931
932
933
934
935
936
937
938
939
940
941
942
943
944
945
946
947
948
949
950
951
952
953
954
955
956
957
958
959
960
961
962
963
964
965
966
967
968
969
970
971
972
973
974
975
976
977
978
979
980
981
982
983
984
985
986
987
988
989
990
991
992
993
994
995
996
997
998
999
1000
1001
1002
1003
1004
1005
1006
1007
1008
1009
1010
1011
1012
1013
1014
1015
1016
1017
1018
1019
1020
1021
1022
1023
1024
1025
1026
1027
1028
1029
1030
1031
1032
1033
1034
1035
1036
1037
1038
1039
1040
1041
1042
1043
1044
1045
1046
1047
1048
1049
1050
1051
1052
1053
1054
1055
1056
1057
1058
1059
1060
1061
1062
1063
1064
1065
1066
1067
1068
1069
1070
1071
1072
1073
1074
1075
1076
1077
1078
1079
1080
1081
1082
1083
1084
1085
1086
1087
1088
1089
1090
1091
1092
1093
1094
1095
1096
1097
1098
1099
1100
1101
1102
1103
1104
1105
1106
1107
1108
1109
1110
1111
1112
1113
1114
1115
1116
1117
1118
1119
1120
1121
1122
1123
1124
1125
1126
1127
1128
1129
1130
1131
1132
1133
1134
1135
1136
1137
1138
1139
1140
1141
1142
1143
1144
1145
1146
1147
1148
1149
1150
1151
1152
1153
1154
1155
1156
1157
1158
1159
1160
1161
1162
1163
1164
1165
1166
1167
1168
1169
1170
1171
1172
1173
1174
1175
1176
1177
1178
1179
1180
1181
1182
1183
1184
1185
1186
1187
1188
1189
1190
1191
1192
1193
1194
1195
1196
1197
1198
1199
1200
1201
1202
1203
1204
1205
1206
1207
1208
1209
1210
1211
1212
1213
1214
1215
1216
1217
1218
1219
1220
1221
1222
1223
1224
1225
1226
1227
1228
1229
1230
1231
1232
1233
1234
1235
1236
1237
1238
1239
1240
1241
1242
1243
1244
1245
1246
1247
1248
1249
1250
1251
1252
1253
1254
1255
1256
1257
1258
1259
1260
1261
1262
1263
1264
1265
1266
1267
1268
1269
1270
1271
1272
1273
1274
1275
1276
1277
1278
1279
1280
1281
1282
1283
1284
1285
1286
1287
1288
1289
1290
1291
1292
1293
1294
1295
1296
1297
1298
1299
1300
1301
1302
1303
1304
1305
1306
1307
1308
1309
1310
1311
1312
1313
1314
1315
1316
1317
1318
1319
1320
1321
1322
1323
1324
1325
1326
1327
1328
1329
1330
1331
1332
1333
1334
1335
1336
1337
1338
1339
1340
1341
1342
1343
1344
1345
1346
1347
1348
1349
1350
1351
1352
1353
1354
1355
1356
1357
1358
1359
1360
1361
1362
1363
1364
1365
1366
1367
1368
1369
1370
1371
1372
1373
1374
1375
1376
1377
1378
1379
1380
1381
1382
1383
1384
1385
1386
1387
1388
1389
1390
1391
1392
1393
1394
1395
1396
1397
1398
1399
1400
1401
1402
1403
1404
1405
1406
1407
1408
1409
1410
1411
1412
1413
1414
1415
1416
1417
1418
1419
1420
1421
1422
1423
1424
1425
1426
1427
1428
1429
1430
1431
1432
1433
1434
1435
1436
1437
1438
1439
1440
1441
1442
1443
1444
1445
1446
1447
1448
1449
1450
1451
1452
1453
1454
1455
1456
1457
1458
1459
1460
1461
1462
1463
1464
1465
1466
1467
1468
1469
1470
1471
1472
1473
1474
1475
1476
1477
1478
1479
1480
1481
1482
1483
1484
1485
1486
1487
1488
1489
1490
1491
1492
1493
1494
1495
1496
1497
1498
1499
1500
1501
1502
1503
1504
1505
1506
1507
1508
1509
1510
1511
1512
1513
1514
1515
1516
1517
1518
1519
1520
1521
1522
1523
1524
1525
1526
1527
1528
1529
1530
1531
1532
1533
1534
1535
1536
1537
1538
1539
1540
1541
1542
1543
1544
1545
1546
1547
1548
1549
1550
1551
1552
1553
1554
1555
1556
1557
1558
1559
1560
1561
1562
1563
1564
1565
1566
1567
1568
1569
1570
1571
1572
1573
1574
1575
1576
1577
1578
1579
1580
1581
1582
1583
1584
1585
1586
1587
1588
1589
1590
1591
1592
1593
1594
1595
1596
1597
1598
1599
1600
1601
1602
1603
1604
1605
1606
1607
1608
1609
1610
1611
1612
1613
1614
1615
1616
1617
1618
1619
1620
1621
1622
1623
1624
1625
1626
1627
1628
1629
1630
1631
1632
1633
1634
1635
1636
1637
1638
1639
1640
1641
1642
1643
1644
1645
1646
1647
1648
1649
1650
1651
1652
1653
1654
1655
1656
1657
1658
1659
1660
1661
1662
1663
1664
1665
1666
1667
1668
1669
1670
1671
1672
1673
1674
1675
1676
1677
1678
1679
1680
1681
1682
1683
1684
1685
1686
1687
1688
1689
1690
1691
1692
1693
1694
1695
1696
1697
1698
1699
1700
1701
1702
1703
1704
1705
1706
1707
1708
1709
1710
1711
1712
1713
1714
1715
1716
1717
1718
1719
1720
1721
1722
1723
1724
1725
1726
1727
1728
1729
1730
1731
1732
1733
1734
1735
1736
1737
1738
1739
1740
1741
1742
1743
1744
1745
1746
1747
1748
1749
1750
1751
1752
1753
1754
1755
1756
1757
1758
1759
1760
1761
1762
1763
1764
1765
1766
1767
1768
1769
1770
1771
1772
1773
1774
1775
1776
1777
1778
1779
1780
1781
1782
1783
1784
1785
1786
1787
1788
1789
1790
1791
1792
1793
1794
1795
1796
1797
1798
1799
1800
1801
1802
1803
1804
1805
1806
1807
1808
1809
1810
1811
1812
1813
1814
1815
1816
1817
1818
1819
1820
1821
1822
1823
1824
1825
1826
1827
1828
1829
1830
1831
1832
1833
1834
1835
1836
1837
1838
1839
1840
1841
1842
1843
1844
1845
1846
1847
1848
1849
1850
1851
1852
1853
1854
1855
1856
1857
1858
1859
1860
1861
1862
1863
1864
1865
1866
1867
1868
1869
1870
1871
1872
1873
1874
1875
1876
1877
1878
1879
1880
1881
1882
1883
1884
1885
1886
1887
1888
1889
1890
1891
1892
1893
1894
1895
1896
1897
1898
1899
1900
1901
1902
1903
1904
1905
1906
1907
1908
1909
1910
1911
1912
1913
1914
1915
1916
1917
1918
1919
1920
1921
1922
1923
1924
1925
1926
1927
1928
1929
1930
1931
1932
1933
1934
1935
1936
1937
1938
1939
1940
1941
1942
1943
1944
1945
1946
1947
1948
1949
1950
1951
1952
1953
1954
1955
1956
1957
1958
1959
1960
1961
1962
1963
1964
1965
1966
1967
1968
1969
1970
1971
1972
1973
1974
1975
1976
1977
1978
1979
1980
1981
1982
1983
1984
1985
1986
1987
1988
1989
1990
1991
1992
1993
1994
1995
1996
1997
1998
1999
2000
2001
2002
2003
2004
2005
2006
2007
2008
2009
2010
2011
2012
2013
2014
2015
2016
2017
2018
2019
2020
2021
2022
2023
2024
2025
2026
2027
2028
2029
2030
2031
2032
2033
2034
2035
2036
2037
2038
2039
2040
2041
2042
2043
2044
2045
2046
2047
2048
2049
2050
2051
2052
2053
2054
2055
2056
2057
2058
2059
2060
2061
2062
2063
2064
2065
2066
2067
2068
2069
2070
2071
2072
2073
2074
2075
2076
2077
2078
2079
2080
2081
2082
2083
2084
2085
2086
2087
2088
2089
2090
2091
2092
2093
2094
2095
2096
2097
2098
2099
2100
2101
2102
2103
2104
2105
2106
2107
2108
2109
2110
2111
2112
2113
2114
2115
2116
2117
2118
2119
2120
2121
2122
2123
2124
2125
2126
2127
2128
2129
2130
2131
2132
2133
2134
2135
2136
2137
2138
2139
2140
2141
2142
2143
2144
2145
2146
2147
2148
2149
2150
2151
2152
2153
2154
2155
2156
2157
2158
2159
2160
2161
2162
2163
2164
2165
2166
2167
2168
2169
2170
2171
2172
2173
2174
2175
2176
2177
2178
2179
2180
2181
2182
2183
2184
2185
2186
2187
2188
2189
2190
2191
2192
2193
2194
2195
2196
2197
2198
2199
2200
2201
2202
2203
2204
2205
2206
2207
2208
2209
2210
2211
2212
2213
2214
2215
2216
2217
2218
2219
2220
2221
2222
2223
2224
2225
2226
2227
2228
2229
2230
2231
2232
2233
2234
2235
2236
2237
2238
2239
2240
2241
2242
2243
2244
2245
2246
2247
2248
2249
2250
2251
2252
2253
2254
2255
2256
2257
2258
2259
2260
2261
2262
2263
2264
2265
2266
2267
2268
2269
2270
2271
2272
2273
2274
2275
2276
2277
2278
2279
2280
2281
2282
2283
2284
2285
2286
2287
2288
2289
2290
2291
2292
2293
2294
2295
2296
2297
2298
2299
2300
2301
2302
2303
2304
2305
2306
2307
2308
2309
2310
2311
2312
2313
2314
2315
2316
2317
2318
2319
2320
2321
2322
2323
2324
2325
2326
2327
2328
2329
2330
2331
2332
2333
2334
2335
2336
2337
2338
2339
2340
2341
2342
2343
2344
2345
2346
2347
2348
2349
2350
2351
2352
2353
2354
2355
2356
2357
2358
2359
2360
2361
2362
2363
2364
2365
2366
2367
2368
2369
2370
2371
2372
2373
2374
2375
2376
2377
2378
2379
2380
2381
2382
2383
2384
2385
2386
2387
2388
2389
2390
2391
2392
2393
2394
2395
2396
2397
2398
2399
2400
2401
2402
2403
2404
2405
2406
2407
2408
2409
2410
2411
2412
2413
2414
2415
2416
2417
2418
2419
2420
2421
2422
2423
2424
2425
2426
2427
2428
2429
2430
2431
2432
2433
2434
2435
2436
2437
2438
2439
2440
2441
2442
2443
2444
2445
2446
2447
2448
2449
2450
2451
2452
2453
2454
2455
2456
2457
2458
2459
2460
2461
2462
2463
2464
2465
2466
2467
2468
2469
2470
2471
2472
2473
2474
2475
2476
2477
2478
2479
2480
2481
2482
2483
2484
2485
2486
2487
2488
2489
2490
2491
2492
2493
2494
2495
2496
2497
2498
2499
2500
2501
2502
2503
2504
2505
2506
2507
2508
2509
2510
2511
2512
2513
2514
2515
2516
2517
2518
2519
2520
2521
2522
2523
2524
2525
2526
2527
2528
2529
2530
2531
2532
2533
2534
2535
2536
2537
2538
2539
2540
2541
2542
2543
2544
2545
2546
2547
2548
2549
2550
2551
2552
2553
2554
2555
2556
2557
2558
2559
2560
2561
2562
2563
2564
2565
2566
2567
2568
2569
2570
2571
2572
2573
2574
2575
2576
2577
2578
2579
2580
2581
2582
2583
2584
2585
2586
2587
2588
2589
2590
2591
2592
2593
2594
2595
2596
2597
2598
2599
2600
2601
2602
2603
2604
2605
2606
2607
2608
2609
2610
2611
2612
2613
2614
2615
2616
2617
2618
2619
2620
2621
2622
2623
2624
2625
2626
2627
2628
2629
2630
2631
2632
2633
2634
2635
2636
2637
2638
2639
2640
2641
2642
2643
2644
2645
2646
2647
2648
2649
2650
2651
2652
2653
2654
2655
2656
|
simdutf: Text processing at billions of characters per second [](https://github.com/simdutf/simdutf/actions/workflows/alpine.yml) [](https://github.com/simdutf/simdutf/actions/workflows/msys2-clang.yml) [](https://github.com/simdutf/simdutf/actions/workflows/ubuntu22-cxx20.yml)
===============================================
<img src="doc/logo.svg" width="25%" style="float: right">
- [Real-World Usage](#real-world-usage)
- [How fast is it?](#how-fast-is-it)
- [Requirements](#requirements)
- [Usage (Usage)](#usage-usage)
- [Usage (CMake)](#usage-cmake)
- [Single-header version](#single-header-version)
- [Single-header version with limited features](#single-header-version-with-limited-features)
- [Packages](#packages)
- [Example](#example)
- [API](#api)
- [Base64](#base64)
- [Find](#find)
- [C++20 and std::span usage in simdutf](#c20-and-stdspan-usage-in-simdutf)
- [The sutf command-line tool](#the-sutf-command-line-tool)
- [Manual implementation selection](#manual-implementation-selection)
- [Thread safety](#thread-safety)
- [References](#references)
- [License](#license)
Most modern software relies on the [Unicode standard](https://en.wikipedia.org/wiki/Unicode).
In memory, Unicode strings are represented using either
UTF-8 or UTF-16. The UTF-8 format is the de facto standard on the web (JSON, HTML, etc.) and it has been adopted as the default in many popular
programming languages (Go, Zig, Rust, Swift, etc.). The UTF-16 format is standard in Java, C# and in many Windows technologies.
Not all sequences of bytes are valid Unicode strings. It is unsafe to use Unicode strings in UTF-8 and UTF-16LE without first validating them. Furthermore, we often need to convert strings from one encoding to another, by a process called [transcoding](https://en.wikipedia.org/wiki/Transcoding). For security purposes, such transcoding should be validating: it should refuse to transcode incorrect strings.
This library provide fast Unicode functions such as
- ASCII, UTF-8, UTF-16LE/BE and UTF-32 validation, with and without error identification,
- Latin1 to UTF-8 transcoding,
- Latin1 to UTF-16LE/BE transcoding
- Latin1 to UTF-32 transcoding
- UTF-8 to Latin1 transcoding, with or without validation, with and without error identification,
- UTF-8 to UTF-16LE/BE transcoding, with or without validation, with and without error identification,
- UTF-8 to UTF-32 transcoding, with or without validation, with and without error identification,
- UTF-16LE/BE to Latin1 transcoding, with or without validation, with and without error identification,
- UTF-16LE/BE to UTF-8 transcoding, with or without validation, with and without error identification,
- UTF-32 to Latin1 transcoding, with or without validation, with and without error identification,
- UTF-32 to UTF-8 transcoding, with or without validation, with and without error identification,
- UTF-32 to UTF-16LE/BE transcoding, with or without validation, with and without error identification,
- UTF-16LE/BE to UTF-32 transcoding, with or without validation, with and without error identification,
- From an UTF-8 string, compute the size of the Latin1 equivalent string,
- From an UTF-8 string, compute the size of the UTF-16 equivalent string,
- From an UTF-8 string, compute the size of the UTF-32 equivalent string (equivalent to UTF-8 character counting),
- From an UTF-16LE/BE string, compute the size of the Latin1 equivalent string,
- From an UTF-16LE/BE string, compute the size of the UTF-8 equivalent string,
- From an UTF-32 string, compute the size of the UTF-8 or UTF-16LE equivalent string,
- From an UTF-16LE/BE string, compute the size of the UTF-32 equivalent string (equivalent to UTF-16 character counting),
- UTF-8 and UTF-16LE/BE character counting,
- UTF-16 endianness change (UTF16-LE/BE to UTF-16-BE/LE),
- [WHATWG forgiving-base64](https://infra.spec.whatwg.org/#forgiving-base64-decode) (with or without URL encoding) to binary,
- Binary to base64 (with or without URL encoding).
The functions are accelerated using SIMD instructions (e.g., ARM NEON, SSE, AVX, AVX-512, RISC-V Vector Extension, LoongSon, POWER, etc.). When your strings contain hundreds of characters, we can often transcode them at speeds exceeding a billion characters per second. You should expect high speeds not only with English strings (ASCII) but also Chinese, Japanese, Arabic, and so forth. We handle the full character range (including, for example, emojis).
The library compiles down to a small library of a few hundred kilobytes. Our functions are exception-free and non allocating. We have extensive tests and extensive benchmarks.
We have exhaustive tests, including an elaborate fuzzing setup. The library has been used in production systems for years.
Real-World Usage
-----
The simdutf library is used by:
- [Node.js](https://nodejs.org/en/) (19.4.0 or better, 20.0 or better, 18.15 or better), a standard JavaScript runtime environment,
- [Bun](https://bun.sh), a fast JavaScript runtime environment,
- [WebKit](https://github.com/WebKit/WebKit/pull/9990), the Web engine behind the Safari browser (iOS, macOS),
- [Chromium](https://chromium-review.googlesource.com/c/chromium/src/+/6054817), the Web engine behind the Google Chrome, Microsoft Edge and Brave,
- [StarRocks](https://www.starrocks.io), an Open-Source, High-Performance Analytical Database,
- [Oracle GraalVM JavaScript](https://github.com/oracle/graaljs), a JavaScript implementation by Oracle,
- [Couchbase](https://www.couchbase.com), a popular database system,
- [Ladybird](https://ladybird.org), an independent Web browser,
- [Cloudflare workerd](https://github.com/cloudflare/workerd), a JavaScript/Wasm Runtime,
- [haskell/text](https://github.com/haskell/text), a library for fast operations over Unicode text,
- [klogg](https://github.com/variar/klogg), a Really fast log explorer,
- [Pixie](https://github.com/pixie-io/pixie), observability tool for Kubernetes applications,
- [vte](https://gitlab.gnome.org/GNOME/vte) (0.81.0 or better), a virtual terminal widget for GTK applications.
How fast is it?
-----------------
The adoption of the simdutf library by the popular Node.js JavaScript runtime lead to a significant
performance gain:
> Decoding and Encoding becomes considerably faster than in Node.js 18. With the addition of simdutf for UTF-8 parsing the observed benchmark, results improved by 364% (an extremely impressive leap) when decoding in comparison to Node.js 16. ([State of Node.js Performance 2023](https://blog.rafaelgss.dev/state-of-nodejs-performance-2023))
<img src="doc/node2023.png" width="70%" />
Over a wide range of realistic data sources, the simdutf library transcodes a billion characters per second or more. Our approach can be 3 to 10 times faster than the popular ICU library on difficult (non-ASCII) strings. We can be 20x faster than ICU when processing easy strings (ASCII). Our good results apply to both recent x64 and ARM processors.
To illustrate, we present a benchmark result with values are in billions of characters processed by second. Consider the following figures.
<img src="doc/utf8utf16.png" width="70%" />
<img src="doc/utf16utf8.png" width="70%" />
If your system supports AVX-512, the simdutf library can provide very high performance. We get the following speed results on an Ice Lake Intel processor (both AVX2 and AVX-512) are simdutf kernels:
<img src="doc/avx512.png" width="70%" />
Datasets: https://github.com/lemire/unicode_lipsum
Please refer to our benchmarking tool for a proper interpretation of the numbers. Our results are reproducible.
Requirements
-------
- C++11 compatible compiler. We support LLVM clang, GCC, Visual Studio. (Our tests and benchmark tools requires C++17.) Be aware that GCC under Windows is buggy and thus unsupported.
- For high speed, you should have a recent 64-bit system (e.g., ARM, x64, RISC-V with vector extensions, Loongson, POWER).
- If you rely on CMake, you should use a recent CMake (at least 3.15); otherwise you may use the [single header version](#single-header-version). The library is also available from [Microsoft's vcpkg](https://github.com/simdutf/simdutf-vcpkg), from [conan](https://conan.io/center/recipes/simdutf), from [FreeBSD's port](https://cgit.freebsd.org/ports/tree/converters/simdutf), from [brew](https://formulae.brew.sh/formula/simdutf), and many other systems.
- AVX-512 support require a processor with AVX512-VBMI2 (Ice Lake or better, AMD Zen 4 or better) and a recent compiler (GCC 8 or better, Visual Studio 2022 or better, LLVM clang 6 or better). You need a correspondingly recent assembler such as gas (2.30+) or nasm (2.14+): recent compilers usually come with recent assemblers. If you mix a recent compiler with an incompatible/old assembler (e.g., when using a recent compiler with an old Linux distribution), you may get errors at build time because the compiler produces instructions that the assembler does not recognize: you should update your assembler to match your compiler (e.g., upgrade binutils to version 2.30 or better under Linux) or use an older compiler matching the capabilities of your assembler.
- To benefit from RISC-V Vector Extensions on RISC-V systems, you should compile specifically for the desired architecture. E.g., add `-march=rv64gcv` as a compiler flag when using a version of GCC or LLVM which supports these extensions (such as GCC 14 or better). The command `CXXFLAGS=-march=rv64gcv cmake -B build` may suffice.
- We recommend that Visual Studio users compile with LLVM (ClangCL). Using LLVM as a front-end inside Visual Studio provides faster release builds and better runtime performance.
Usage (Usage)
-------
We made a video to help you get started with the library.
[](https://www.youtube.com/watch?v=H9NZtb7ykYs)<br />
Quick Start
-----------
Linux or macOS users might follow the following instructions if they have a recent C++ compiler installed and the standard utilities (`wget`, `unzip`, etc.)
1. Pull the library in a directory
```
wget https://github.com/simdutf/simdutf/releases/download/v7.7.1/singleheader.zip
unzip singleheader.zip
```
You can replace `wget` by `curl -OL https://...` if you prefer.
2. Compile
```
c++ -std=c++17 -o amalgamation_demo amalgamation_demo.cpp
```
3. `./amalgamation_demo`
```
valid UTF-8
wrote 4 UTF-16LE words.
valid UTF-16LE
wrote 4 UTF-8 words.
1234
perfect round trip
```
*We strongly discourage working from our main git branch. You should never use our main branch
in production. [Use our releases](https://github.com/simdutf/simdutf/releases/). They are tagged as `vX.Y.Z`.*
Usage (CMake)
-------
```
cmake -B build
cmake --build build
cd build
ctest .
```
Visual Studio users must specify whether they want to build the Release or Debug version.
To run transcoding benchmarks, execute the `benchmark` command. You can get help on its
usage by first building it and then calling it with the `--help` flag.
E.g., under Linux you may do the following:
```
cmake -B build -D SIMDUTF_BENCHMARKS=ON
cmake --build build
./build/benchmarks/benchmark --help
./build/benchmarks/base64/base64_benchmark --help
```
E.g., to run base64 decoding benchmarks on DNS data (short inputs), do
```
./build/benchmarks/base64/benchmark_base64 -d pathto/base64data/dns/*.txt
```
where pathto/base64data should contain the path to a clone of
the repository https://github.com/lemire/base64data.
Instructions are similar for Visual Studio users.
To use the library as a CMake dependency in your project, please see `tests/installation_tests/from_fetch` for
an example.
Since ICU is so common and popular, we assume that you may have it already on your system. When
it is not found, it is simply omitted from the benchmarks. Thus, to benchmark against ICU, make
sure you have ICU installed on your machine and that cmake can find it. For macOS, you may
install it with brew using `brew install icu4c`. If you have ICU on your system but cmake cannot
find it, you may need to provide cmake with a path to ICU, such as `ICU_ROOT=/usr/local/opt/icu4c cmake -B build`.
You may also use a package manager. E.g., [we have a complete example using vcpkg](https://github.com/simdutf/simdutf-vcpkg).
Single-header version
----------------------
You can create a single-header version of the library where
all of the code is put into two files (`simdutf.h` and `simdutf.cpp`).
We publish a zip archive containing these files, e.g., see
https://github.com/simdutf/simdutf/releases/download/v7.7.1/singleheader.zip
You may generate it on your own using a Python script.
```
python3 ./singleheader/amalgamate.py
```
We require Python 3 or better.
Under Linux and macOS, you may test it as follows:
```
cd singleheader
c++ -o amalgamation_demo amalgamation_demo.cpp -std=c++17
./amalgamation_demo
```
Single-header version with limited features
-------------------------------------------
When creating a single-header version, it is possible to limit which
features are enabled. Then the API of library is limited too and the
amalgamated sources do not include code related to disabled features.
The script `singleheader/amalgamate.py` accepts the following parameters:
* `--with-utf8` - procedures related only to UTF-8 encoding (like string validation);
* `--with-utf16` - likewise: only UTF-16 encoding;
* `--with-utf32` - likewise: only UTF-32 encoding;
* `--with-ascii` - procedures related to ASCII encoding;
* `--with-latin1` - convert between selected UTF encodings and Latin1;
* `--with-base64` - procedures related to Base64 encoding, includes 'find';
* `--with-detect-enc` - enable detect encoding.
If we need conversion between different encodings, like UTF-8 and UTF-32, then
these two features have to be enabled.
The amalgamated sources set to 1 the following preprocessor defines:
* `SIMDUTF_FEATURE_UTF8`,
* `SIMDUTF_FEATURE_UTF16`,
* `SIMDUTF_FEATURE_UTF32`,
* `SIMDUTF_FEATURE_ASCII`,
* `SIMDUTF_FEATURE_LATIN1`,
* `SIMDUTF_FEATURE_BASE64`,
* `SIMDUTF_FEATURE_DETECT_ENCODING`.
Thus, when it is needed to make sure the correct set of features are
enabled, we may test it using preprocessor:
```cpp
#if SIMDUTF_FEATURE_UTF16 || SIMDUTF_FEATURE_UTF32
#error "Please amalagamate simdutf without UTF-16 and UTF-32"
#endif
```
Packages
------
[](https://repology.org/project/simdutf/versions)
Example
---------
Using the single-header version, you could compile the following program.
```cpp
#include <iostream>
#include <memory>
#include "simdutf.cpp"
#include "simdutf.h"
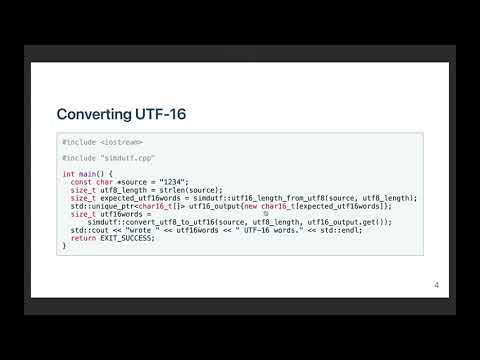
int main(int argc, char *argv[]) {
const char *source = "1234";
// 4 == strlen(source)
bool validutf8 = simdutf::validate_utf8(source, 4);
if (validutf8) {
std::cout << "valid UTF-8" << std::endl;
} else {
std::cerr << "invalid UTF-8" << std::endl;
return EXIT_FAILURE;
}
// We need a buffer of size where to write the UTF-16LE code units.
size_t expected_utf16words = simdutf::utf16_length_from_utf8(source, 4);
std::unique_ptr<char16_t[]> utf16_output{new char16_t[expected_utf16words]};
// convert to UTF-16LE
size_t utf16words =
simdutf::convert_utf8_to_utf16le(source, 4, utf16_output.get());
std::cout << "wrote " << utf16words << " UTF-16LE code units." << std::endl;
// It wrote utf16words * sizeof(char16_t) bytes.
bool validutf16 = simdutf::validate_utf16le(utf16_output.get(), utf16words);
if (validutf16) {
std::cout << "valid UTF-16LE" << std::endl;
} else {
std::cerr << "invalid UTF-16LE" << std::endl;
return EXIT_FAILURE;
}
// convert it back:
// We need a buffer of size where to write the UTF-8 code units.
size_t expected_utf8words =
simdutf::utf8_length_from_utf16le(utf16_output.get(), utf16words);
std::unique_ptr<char[]> utf8_output{new char[expected_utf8words]};
// convert to UTF-8
size_t utf8words = simdutf::convert_utf16le_to_utf8(
utf16_output.get(), utf16words, utf8_output.get());
std::cout << "wrote " << utf8words << " UTF-8 code units." << std::endl;
std::string final_string(utf8_output.get(), utf8words);
std::cout << final_string << std::endl;
if (final_string != source) {
std::cerr << "bad conversion" << std::endl;
return EXIT_FAILURE;
} else {
std::cerr << "perfect round trip" << std::endl;
}
return EXIT_SUCCESS;
}
```
API
-----
Our API is made of a few non-allocating functions. They typically take a pointer and a length as a parameter,
and they sometimes take a pointer to an output buffer. Users are responsible for memory allocation.
We use three types of data pointer types:
- `char*` for UTF-8 or indeterminate Unicode formats,
- `char16_t*` for UTF-16 (both UTF-16LE and UTF-16BE),
- `char32_t*` for UTF-32. UTF-32 is primarily used for internal use, not data interchange. Thus, unless otherwise stated, `char32_t` refers to the native type and is typically UTF-32LE since virtually all systems are little-endian today.
In generic terms, we refer to `char`, `char16_t`, and `char32_t` as *code units*. A *character* may use several *code units*: between 1 and 4 code units in UTF-8, and between
1 and 2 code units in UTF-16LE and UTF-16BE.
Our functions and declarations are all in the `simdutf` namespace. Thus you should prefix our functions
and types with `simdutf::` as required.
If using C++20, all functions which take a pointer and a size (which is almost all of them)
also have a span overload. Here is an example:
```cpp
std::vector<char> data{1, 2, 3, 4, 5};
// C++11 API
auto cpp11 = simdutf::autodetect_encoding(data.data(), data.size());
// C++20 API
auto cpp20 = simdutf::autodetect_encoding(data);
```
The span overloads use std::span for UTF-16 and UTF-32. For latin1, UTF-8,
"binary" (used by the base64 functions) anything that has a `.size()` and
`.data()` that returns a pointer to a byte-like type will be accepted as a
span. This makes it possible to directly pass std::string, std::string_view,
std::vector, std::array and std::span to the functions. The reason for allowing
all byte-like types in the api (as opposed to only `std::span<char>`) is to
make it easy to interface with whatever data the user may have, without having
to resort to casting.
We have basic functions to detect the type of an input. They return an integer defined by
the following `enum`.
```cpp
enum encoding_type {
UTF8 = 1, // BOM 0xef 0xbb 0xbf
UTF16_LE = 2, // BOM 0xff 0xfe
UTF16_BE = 4, // BOM 0xfe 0xff
UTF32_LE = 8, // BOM 0xff 0xfe 0x00 0x00
UTF32_BE = 16, // BOM 0x00 0x00 0xfe 0xff
unspecified = 0
};
```
```cpp
/**
* Autodetect the encoding of the input, a single encoding is recommended.
* E.g., the function might return simdutf::encoding_type::UTF8,
* simdutf::encoding_type::UTF16_LE, simdutf::encoding_type::UTF16_BE, or
* simdutf::encoding_type::UTF32_LE.
*
* @param input the string to analyze.
* @param length the length of the string in bytes.
* @return the detected encoding type
*/
simdutf_warn_unused simdutf::encoding_type autodetect_encoding(const char *input, size_t length) noexcept;
/**
* Autodetect the possible encodings of the input in one pass.
* E.g., if the input might be UTF-16LE or UTF-8, this function returns
* the value (simdutf::encoding_type::UTF8 | simdutf::encoding_type::UTF16_LE).
*
* @param input the string to analyze.
* @param length the length of the string in bytes.
* @return the detected encoding type
*/
simdutf_warn_unused int detect_encodings(const char *input, size_t length) noexcept;
```
For validation and transcoding, we also provide functions that will stop on error and return a result struct which is a pair of two fields:
```cpp
struct result {
error_code error; // see `struct error_code`.
size_t count; // In case of error, indicates the position of the error in the input in code units.
// In case of success, indicates the number of code units validated/written.
};
```
On error, the `error` field indicates the type of error encountered and the `count` field indicates the position of the error in the input in code units or the number of characters validated/written.
We report six types of errors related to Latin1, UTF-8, UTF-16 and UTF-32 encodings:
```cpp
enum error_code {
SUCCESS = 0,
HEADER_BITS, // Any byte must have fewer than 5 header bits.
TOO_SHORT, // The leading byte must be followed by N-1 continuation bytes,
// where N is the UTF-8 character length This is also the error
// when the input is truncated.
TOO_LONG, // We either have too many consecutive continuation bytes or the
// string starts with a continuation byte.
OVERLONG, // The decoded character must be above U+7F for two-byte characters,
// U+7FF for three-byte characters, and U+FFFF for four-byte
// characters.
TOO_LARGE, // The decoded character must be less than or equal to
// U+10FFFF,less than or equal than U+7F for ASCII OR less than
// equal than U+FF for Latin1
SURROGATE, // The decoded character must be not be in U+D800...DFFF (UTF-8 or
// UTF-32)
// OR
// a high surrogate must be followed by a low surrogate
// and a low surrogate must be preceded by a high surrogate
// (UTF-16)
// OR
// there must be no surrogate at all and one is
// found (Latin1 functions)
// OR
// *specifically* for the function
// utf8_length_from_utf16_with_replacement, a surrogate (whether
// in error or not) has been found (I.e., whether we are in the
// Basic Multilingual Plane or not).
INVALID_BASE64_CHARACTER, // Found a character that cannot be part of a valid
// base64 string. This may include a misplaced padding character ('=').
BASE64_INPUT_REMAINDER, // The base64 input terminates with a single
// character, excluding padding (=). It is also used
// in strict mode when padding is not adequate.
BASE64_EXTRA_BITS, // The base64 input terminates with non-zero
// padding bits.
OUTPUT_BUFFER_TOO_SMALL, // The provided buffer is too small.
OTHER // Not related to validation/transcoding.
};
```
On success, the `error` field is set to `SUCCESS` and the `position` field indicates either the number of code units validated for validation functions or the number of written
code units in the output format for transcoding functions. In ASCII, Latin1 and UTF-8, code units occupy 8 bits (they are bytes); in UTF-16LE and UTF-16BE, code units occupy 16 bits; in UTF-32, code units occupy 32 bits.
Generally speaking, functions that report errors always stop soon after an error is
encountered and might therefore be faster on inputs where an error occurs early in the input.
The functions that return a boolean indicating whether or not an error has been encountered
are meant to be used in an *optimistic setting*---when we expect that inputs will almost always
be correct.
You may use functions that report an error to indicate where the problem happens during, as follows:
```cpp
std::string bad_ascii = "\x20\x20\x20\x20\x20\xff\x20\x20\x20";
simdutf::result res = simdtuf::validate_ascii_with_errors(bad_ascii.data(), bad_ascii.size());
if(res.error != simdutf::error_code::SUCCESS) {
std::cerr << "error at index " << res.count << std::endl;
}
```
Or as follows:
```cpp
std::string bad_utf8 = "\xc3\xa9\xc3\xa9\x20\xff\xc3\xa9";
simdutf::result res = simdtuf::validate_utf8_with_errors(bad_utf8.data(), bad_utf8.size());
if(res.error != simdutf::error_code::SUCCESS) {
std::cerr << "error at index " << res.count << std::endl;
}
res = simdtuf::validate_utf8_with_errors(bad_utf8.data(), res.count);
// will be successful in this case
if(res.error == simdutf::error_code::SUCCESS) {
std::cerr << "we have " << res.count << "valid bytes" << std::endl;
}
```
We have fast validation functions.
```cpp
/**
* Validate the ASCII string.
*
* @param buf the ASCII string to validate.
* @param len the length of the string in bytes.
* @return true if and only if the string is valid ASCII.
*/
simdutf_warn_unused bool validate_ascii(const char *buf, size_t len) noexcept;
/**
* Validate the ASCII string and stop on error.
*
* @param buf the ASCII string to validate.
* @param len the length of the string in bytes.
* @return a result pair struct (of type simdutf::result containing the two fields error and count) with an error code and either position of the error (in the input in code units) if any, or the number of code units validated if successful.
*/
simdutf_warn_unused result validate_ascii_with_errors(const char *buf, size_t len) noexcept;
/**
* Validate the ASCII string as a UTF-16 sequence.
* An UTF-16 sequence is considered an ASCII sequence
* if it could be converted to an ASCII string losslessly.
*
* @param buf the UTF-16 string to validate.
* @param len the length of the string in bytes.
* @return true if and only if the string is valid ASCII.
*/
simdutf_warn_unused bool validate_utf16_as_ascii(const char16_t *buf,
size_t len) noexcept;
/**
* Validate the ASCII string as a UTF-16BE sequence.
* An UTF-16 sequence is considered an ASCII sequence
* if it could be converted to an ASCII string losslessly.
*
* @param buf the UTF-16BE string to validate.
* @param len the length of the string in bytes.
* @return true if and only if the string is valid ASCII.
*/
simdutf_warn_unused bool validate_utf16be_as_ascii(const char16_t *buf,
size_t len) noexcept;
/**
* Validate the ASCII string as a UTF-16LE sequence.
* An UTF-16 sequence is considered an ASCII sequence
* if it could be converted to an ASCII string losslessly.
*
* @param buf the UTF-16LE string to validate.
* @param len the length of the string in bytes.
* @return true if and only if the string is valid ASCII.
*/
simdutf_warn_unused bool validate_utf16le_as_ascii(const char16_t *buf,
size_t len) noexcept;
/**
* Validate the UTF-8 string. This function may be best when you expect
* the input to be almost always valid. Otherwise, consider using
* validate_utf8_with_errors.
*
* @param buf the UTF-8 string to validate.
* @param len the length of the string in bytes.
* @return true if and only if the string is valid UTF-8.
*/
simdutf_warn_unused bool validate_utf8(const char *buf, size_t len) noexcept;
/**
* Validate the UTF-8 string and stop on error. It might be faster than
* validate_utf8 when an error is expected to occur early.
*
* @param buf the UTF-8 string to validate.
* @param len the length of the string in bytes.
* @return a result pair struct (of type simdutf::result containing the two fields error and count) with an error code and either position of the error (in the input in code units) if any, or the number of code units validated if successful.
*/
simdutf_warn_unused result validate_utf8_with_errors(const char *buf, size_t len) noexcept;
/**
* Using native endianness; Validate the UTF-16 string.
* This function may be best when you expect the input to be almost always valid.
* Otherwise, consider using validate_utf16_with_errors.
*
* This function is not BOM-aware.
*
* @param buf the UTF-16 string to validate.
* @param len the length of the string in number of 2-byte code units (char16_t).
* @return true if and only if the string is valid UTF-16.
*/
simdutf_warn_unused bool validate_utf16(const char16_t *buf, size_t len) noexcept;
/**
* Validate the UTF-16LE string. This function may be best when you expect
* the input to be almost always valid. Otherwise, consider using
* validate_utf16le_with_errors.
*
* This function is not BOM-aware.
*
* @param buf the UTF-16LE string to validate.
* @param len the length of the string in number of 2-byte code units (char16_t).
* @return true if and only if the string is valid UTF-16LE.
*/
simdutf_warn_unused bool validate_utf16le(const char16_t *buf, size_t len) noexcept;
/**
* Validate the UTF-16BE string. This function may be best when you expect
* the input to be almost always valid. Otherwise, consider using
* validate_utf16be_with_errors.
*
* This function is not BOM-aware.
*
* @param buf the UTF-16BE string to validate.
* @param len the length of the string in number of 2-byte code units (char16_t).
* @return true if and only if the string is valid UTF-16BE.
*/
simdutf_warn_unused bool validate_utf16be(const char16_t *buf, size_t len) noexcept;
/**
* Using native endianness; Validate the UTF-16 string and stop on error.
* It might be faster than validate_utf16 when an error is expected to occur early.
*
* This function is not BOM-aware.
*
* @param buf the UTF-16 string to validate.
* @param len the length of the string in number of 2-byte code units (char16_t).
* @return a result pair struct (of type simdutf::result containing the two fields error and count) with an error code and either position of the error (in the input in code units) if any, or the number of code units validated if successful.
*/
simdutf_warn_unused result validate_utf16_with_errors(const char16_t *buf, size_t len) noexcept;
/**
* Validate the UTF-16LE string and stop on error. It might be faster than
* validate_utf16le when an error is expected to occur early.
*
* This function is not BOM-aware.
*
* @param buf the UTF-16LE string to validate.
* @param len the length of the string in number of 2-byte code units (char16_t).
* @return a result pair struct (of type simdutf::result containing the two fields error and count) with an error code and either position of the error (in the input in code units) if any, or the number of code units validated if successful.
*/
simdutf_warn_unused result validate_utf16le_with_errors(const char16_t *buf, size_t len) noexcept;
/**
* Validate the UTF-16BE string and stop on error. It might be faster than
* validate_utf16be when an error is expected to occur early.
*
* This function is not BOM-aware.
*
* @param buf the UTF-16BE string to validate.
* @param len the length of the string in number of 2-byte code units (char16_t).
* @return a result pair struct (of type simdutf::result containing the two fields error and count) with an error code and either position of the error (in the input in code units) if any, or the number of code units validated if successful.
*/
simdutf_warn_unused result validate_utf16be_with_errors(const char16_t *buf, size_t len) noexcept;
/**
* Validate the UTF-32 string.
*
* This function is not BOM-aware.
*
* @param buf the UTF-32 string to validate.
* @param len the length of the string in number of 4-byte code units (char32_t).
* @return true if and only if the string is valid UTF-32.
*/
simdutf_warn_unused bool validate_utf32(const char32_t *buf, size_t len) noexcept;
/**
* Validate the UTF-32 string and stop on error.
*
* This function is not BOM-aware.
*
* @param buf the UTF-32 string to validate.
* @param len the length of the string in number of 4-byte code units (char32_t).
* @return a result pair struct (of type simdutf::result containing the two fields error and count) with an error code and either position of the error (in the input in code units) if any, or the number of code units validated if successful.
*/
simdutf_warn_unused result validate_utf32_with_errors(const char32_t *buf, size_t len) noexcept;
```
Given a potentially invalid UTF-16 input, you may want to make it correct, by using
a replacement character whenever needed. We have fast functions for this purpose
(`to_well_formed_utf16`, `to_well_formed_utf16le`, and `to_well_formed_utf16be`).
They can either copy the string while fixing it, or they can be used to fix
a string in-place.
```cpp
/**
* Fixes an ill-formed UTF-16LE string by replacing mismatched surrogates with
* the Unicode replacement character U+FFFD. If input and output points to
* different memory areas, the procedure copies string, and it's expected that
* output memory is at least as big as the input. It's also possible to set
* input equal output, that makes replacements an in-place operation.
*
* @param input the UTF-16LE string to correct.
* @param len the length of the string in number of 2-byte code units
* (char16_t).
* @param output the output buffer.
*/
void to_well_formed_utf16le(const char16_t *input, size_t len,
char16_t *output) noexcept;
/**
* Fixes an ill-formed UTF-16BE string by replacing mismatched surrogates with
* the Unicode replacement character U+FFFD. If input and output points to
* different memory areas, the procedure copies string, and it's expected that
* output memory is at least as big as the input. It's also possible to set
* input equal output, that makes replacements an in-place operation.
*
* @param input the UTF-16BE string to correct.
* @param len the length of the string in number of 2-byte code units
* (char16_t).
* @param output the output buffer.
*/
void to_well_formed_utf16be(const char16_t *input, size_t len,
char16_t *output) noexcept;
/**
* Fixes an ill-formed UTF-16 string by replacing mismatched surrogates with the
* Unicode replacement character U+FFFD. If input and output points to different
* memory areas, the procedure copies string, and it's expected that output
* memory is at least as big as the input. It's also possible to set input equal
* output, that makes replacements an in-place operation.
*
* @param input the UTF-16 string to correct.
* @param len the length of the string in number of 2-byte code units
* (char16_t).
* @param output the output buffer.
*/
void to_well_formed_utf16(const char16_t *input, size_t len,
char16_t *output) noexcept;
```
Given a valid UTF-8 or UTF-16 input, you may count the number Unicode characters using
fast functions. For UTF-32, there is no need for a function given that each character
requires a flat 4 bytes. Likewise for Latin1: one byte will always equal one character.
```cpp
/**
* Count the number of code points (characters) in the string assuming that
* it is valid.
*
* This function assumes that the input string is valid UTF-16 (native endianness).
* It is acceptable to pass invalid UTF-16 strings but in such cases
* the result is implementation defined.
*
* This function is not BOM-aware.
*
* @param input the UTF-16 string to process
* @param length the length of the string in 2-byte code units (char16_t)
* @return number of code points
*/
simdutf_warn_unused size_t count_utf16(const char16_t * input, size_t length) noexcept;
/**
* Count the number of code points (characters) in the string assuming that
* it is valid.
*
* This function assumes that the input string is valid UTF-16LE.
* It is acceptable to pass invalid UTF-16 strings but in such cases
* the result is implementation defined.
*
* This function is not BOM-aware.
*
* @param input the UTF-16LE string to process
* @param length the length of the string in 2-byte code units (char16_t)
* @return number of code points
*/
simdutf_warn_unused size_t count_utf16le(const char16_t * input, size_t length) noexcept;
/**
* Count the number of code points (characters) in the string assuming that
* it is valid.
*
* This function assumes that the input string is valid UTF-16BE.
* It is acceptable to pass invalid UTF-16 strings but in such cases
* the result is implementation defined.
*
* This function is not BOM-aware.
*
* @param input the UTF-16BE string to process
* @param length the length of the string in 2-byte code units (char16_t)
* @return number of code points
*/
simdutf_warn_unused size_t count_utf16be(const char16_t * input, size_t length) noexcept;
/**
* Count the number of code points (characters) in the string assuming that
* it is valid.
*
* This function assumes that the input string is valid UTF-8.
* It is acceptable to pass invalid UTF-8 strings but in such cases
* the result is implementation defined.
*
* @param input the UTF-8 string to process
* @param length the length of the string in bytes
* @return number of code points
*/
simdutf_warn_unused size_t count_utf8(const char * input, size_t length) noexcept;
```
Prior to transcoding an input, you need to allocate enough memory to receive the result.
We have fast function that scan the input and compute the size of the output. These functions
are fast and non-validating.
```cpp
/**
* Return the number of bytes that this Latin1 string would require in UTF-8 format.
*
* @param input the Latin1 string to convert
* @param length the length of the string bytes
* @return the number of bytes required to encode the Latin1 string as UTF-8
*/
simdutf_warn_unused size_t utf8_length_from_latin1(const char * input, size_t length) noexcept;
/**
* Compute the number of bytes that this UTF-8 string would require in Latin1 format.
*
* This function does not validate the input. It is acceptable to pass invalid UTF-8 strings but in such cases
* the result is implementation defined.
*
* This function is not BOM-aware.
*
* @param input the UTF-8 string to convert
* @param length the length of the string in byte
* @return the number of bytes required to encode the UTF-8 string as Latin1
*/
simdutf_warn_unused size_t latin1_length_from_utf8(const char * input, size_t length) noexcept;
/**
* Compute the number of bytes that this UTF-16 string would require in Latin1 format.
*
* @param length the length of the string in Latin1 code units (char)
* @return the length of the string in Latin1 code units (char) required to encode the UTF-16 string as Latin1
*/
simdutf_warn_unused size_t latin1_length_from_utf16(size_t length) noexcept;
/*
* Compute the number of bytes that this UTF-16LE/BE string would require in Latin1 format.
*
* This function does not validate the input. It is acceptable to pass invalid UTF-16 strings but in such cases
* the result is implementation defined.
*
* This function is not BOM-aware.
*
* @param length the length of the string in 2-byte code units (char16_t)
* @return the number of bytes required to encode the UTF-16LE string as Latin1
*/
simdutf_warn_unused size_t latin1_length_from_utf16(size_t length) noexcept;
/**
* Compute the number of bytes that this UTF-32 string would require in Latin1 format.
*
* This function does not validate the input. It is acceptable to pass invalid UTF-32 strings but in such cases
* the result is implementation defined.
*
* This function is not BOM-aware.
*
* @param length the length of the string in 4-byte code units (char32_t)
* @return the number of bytes required to encode the UTF-32 string as Latin1
*/
simdutf_warn_unused size_t latin1_length_from_utf32(size_t length) noexcept;
/**
* Compute the number of 2-byte code units that this UTF-8 string would require in UTF-16 format.
*
* This function does not validate the input. It is acceptable to pass invalid UTF-8 strings but in such cases
* the result is implementation defined.
*
* @param input the UTF-8 string to process
* @param length the length of the string in bytes
* @return the number of char16_t code units required to encode the UTF-8 string as UTF-16
*/
simdutf_warn_unused size_t utf16_length_from_utf8(const char * input, size_t length) noexcept;
/**
* Compute the number of 4-byte code units that this UTF-8 string would require in UTF-32 format.
*
* This function is equivalent to count_utf8
*
* This function does not validate the input. It is acceptable to pass invalid UTF-8 strings but in such cases
* the result is implementation defined.
*
* This function is not BOM-aware.
*
* @param input the UTF-8 string to process
* @param length the length of the string in bytes
* @return the number of char32_t code units required to encode the UTF-8 string as UTF-32
*/
simdutf_warn_unused size_t utf32_length_from_utf8(const char * input, size_t length) noexcept;
/**
* Using native endianness; Compute the number of bytes that this UTF-16
* string would require in UTF-8 format.
*
* This function does not validate the input. It is acceptable to pass invalid UTF-16 strings but in such cases
* the result is implementation defined.
*
* @param input the UTF-16 string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @return the number of bytes required to encode the UTF-16LE string as UTF-8
*/
simdutf_warn_unused size_t utf8_length_from_utf16(const char16_t * input, size_t length) noexcept;
/**
* Using native endianness; compute the number of bytes that this UTF-16
* string would require in UTF-8 format even when the UTF-16 content contains mismatched
* surrogates that have to be replaced by the replacement character (0xFFFD).
*
* @param input the UTF-16 string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @return the number of bytes required to encode the UTF-16 string as UTF-8
* @return a result pair struct (of type simdutf::result containing the two fields error and count)
* where the count is the number of bytes required to encode the UTF-16 string as UTF-8, and the
* error code is either SUCCESS or SURROGATE. The count is correct regardless of the error field.
* When SURROGATE is returned, it does not indicate an error in the case of this function:
* it indicates that at least one surrogate has been encountered: the surrogates may be matched
* or not (thus this function does not validate). If the returned error code is SUCCESS,
* then the input contains no surrogate, is in the Basic Multilingual Plane, and is necessarily valid.
*/
simdutf_warn_unused result utf8_length_from_utf16_with_replacement(const char16_t *input,
size_t length) noexcept;
/**
* Compute the number of bytes that this UTF-16LE string would require in UTF-8 format.
*
* This function does not validate the input. It is acceptable to pass invalid UTF-16 strings but in such cases
* the result is implementation defined.
*
* @param input the UTF-16LE string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @return the number of bytes required to encode the UTF-16LE string as UTF-8
*/
simdutf_warn_unused size_t utf8_length_from_utf16le(const char16_t * input, size_t length) noexcept;
/**
* Compute the number of bytes that this UTF-16BE string would require in UTF-8 format.
*
* This function does not validate the input. It is acceptable to pass invalid UTF-16 strings but in such cases
* the result is implementation defined.
*
* @param input the UTF-16BE string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @return the number of bytes required to encode the UTF-16BE string as UTF-8
*/
simdutf_warn_unused size_t utf8_length_from_utf16be(const char16_t * input, size_t length) noexcept;
/**
* Compute the number of bytes that this UTF-16LE string would require in UTF-8
* format even when the UTF-16LE content contains mismatched surrogates
* that have to be replaced by the replacement character (0xFFFD).
*
* @param input the UTF-16LE string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @return the number of bytes required to encode the UTF-16LE string as UTF-8
* @return a result pair struct (of type simdutf::result containing the two fields error and count)
* where the count is the number of bytes required to encode the UTF-16LE string as UTF-8, and the
* error code is either SUCCESS or SURROGATE. The count is correct regardless of the error field.
* When SURROGATE is returned, it does not indicate an error in the case of this function:
* it indicates that at least one surrogate has been encountered: the surrogates may be matched
* or not (thus this function does not validate). If the returned error code is SUCCESS,
* then the input contains no surrogate, is in the Basic Multilingual Plane, and is necessarily valid.
*/
simdutf_warn_unused result utf8_length_from_utf16le_with_replacement(
const char16_t *input, size_t length) noexcept;
/**
* Compute the number of bytes that this UTF-16BE string would require in UTF-8
* format even when the UTF-16BE content contains mismatched surrogates
* that have to be replaced by the replacement character (0xFFFD).
*
* @param input the UTF-16BE string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @return a result pair struct (of type simdutf::result containing the two fields error and count)
* where the count is the number of bytes required to encode the UTF-16LE string as UTF-8, and
* the error code is either SUCCESS or SURROGATE. The count is correct regardless of the error field.
* When SURROGATE is returned, it does not indicate an error in the case of this function:
* it indicates that at least one surrogate has been encountered: the surrogates may be matched
* or not (thus this function does not validate). If the returned error code is SUCCESS,
* then the input contains no surrogate, is in the Basic Multilingual Plane, and is necessarily valid.
*/
simdutf_warn_unused result utf8_length_from_utf16be_with_replacement(
const char16_t *input, size_t length) noexcept;
/**
* Compute the number of bytes that this UTF-16LE string would require in UTF-8
* format even when the UTF-16LE content contains mismatched surrogates
* that have to be replaced by the replacement character (0xFFFD).
*
* @param input the UTF-16LE string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @return a result pair struct (of type simdutf::result containing the two fields error and count) where the count is the number of bytes required to encode the UTF-16LE string as UTF-8, and the error code is either SUCCESS or SURROGATE. The count is correct regardless of the error field.
*/
simdutf_warn_unused result utf8_length_from_utf16le_with_replacement(
const char16_t *input, size_t length) noexcept;
/**
* Compute the number of bytes that this UTF-16BE string would require in UTF-8
* format even when the UTF-16BE content contains mismatched surrogates
* that have to be replaced by the replacement character (0xFFFD).
*
* @param input the UTF-16BE string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @return a result pair struct (of type simdutf::result containing the two fields error and count) where the count is the number of bytes required to encode the UTF-16LE string as UTF-8, and the error code is either SUCCESS or SURROGATE. The count is correct regardless of the error field.
*/
simdutf_warn_unused result utf8_length_from_utf16be_with_replacement(
const char16_t *input, size_t length) noexcept;
/**
* Compute the number of bytes that this UTF-32 string would require in UTF-8 format.
*
* This function does not validate the input. It is acceptable to pass invalid UTF-32 strings but in such cases
* the result is implementation defined.
*
* @param input the UTF-32 string to convert
* @param length the length of the string in 4-byte code units (char32_t)
* @return the number of bytes required to encode the UTF-32 string as UTF-8
*/
simdutf_warn_unused size_t utf8_length_from_utf32(const char32_t * input, size_t length) noexcept;
/**
* Compute the number of two-byte code units that this UTF-32 string would require in UTF-16 format.
*
* This function does not validate the input. It is acceptable to pass invalid UTF-32 strings but in such cases
* the result is implementation defined.
*
* @param input the UTF-32 string to convert
* @param length the length of the string in 4-byte code units (char32_t)
* @return the number of bytes required to encode the UTF-32 string as UTF-16
*/
simdutf_warn_unused size_t utf16_length_from_utf32(const char32_t * input, size_t length) noexcept;
/**
* Compute the number of code units that this Latin1 string would require in UTF-16 format.
*
* @param length the length of the string in Latin1 code units (char)
* @return the length of the string in 2-byte code units (char16_t) required to encode the Latin1 string as UTF-16
*/
simdutf_warn_unused size_t utf16_length_from_latin1(size_t length) noexcept;
/**
* Using native endianness; Compute the number of bytes that this UTF-16
* string would require in UTF-32 format.
*
* This function is equivalent to count_utf16.
*
* This function does not validate the input. It is acceptable to pass invalid UTF-16 strings but in such cases
* the result is implementation defined.
*
* This function is not BOM-aware.
*
* @param input the UTF-16 string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @return the number of bytes required to encode the UTF-16LE string as UTF-32
*/
simdutf_warn_unused size_t utf32_length_from_utf16(const char16_t * input, size_t length) noexcept;
/**
* Compute the number of bytes that this UTF-16LE string would require in UTF-32 format.
*
* This function is equivalent to count_utf16le.
*
* This function does not validate the input. It is acceptable to pass invalid UTF-16 strings but in such cases
* the result is implementation defined.
*
* This function is not BOM-aware.
*
* @param input the UTF-16LE string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @return the number of bytes required to encode the UTF-16LE string as UTF-32
*/
simdutf_warn_unused size_t utf32_length_from_utf16le(const char16_t * input, size_t length) noexcept;
/**
* Compute the number of bytes that this UTF-16BE string would require in UTF-32 format.
*
* This function is equivalent to count_utf16be.
*
* This function does not validate the input. It is acceptable to pass invalid UTF-16 strings but in such cases
* the result is implementation defined.
*
* This function is not BOM-aware.
*
* @param input the UTF-16BE string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @return the number of bytes required to encode the UTF-16BE string as UTF-32
*/
simdutf_warn_unused size_t utf32_length_from_utf16be(const char16_t * input, size_t length) noexcept;
/**
* Compute the number of bytes that this Latin1 string would require in UTF-32 format.
*
* @param length the length of the string in Latin1 code units (char)
* @return the length of the string in 4-byte code units (char32_t) required to encode the Latin1 string as UTF-32
*/
simdutf_warn_unused size_t utf32_length_from_latin1(size_t length) noexcept;
```
We have a wide range of conversion between Latin1, UTF-8, UTF-16 and UTF-32. They assume
that you are allocated sufficient memory for the input. The simplest conversion
function output a single integer representing the size of the input, with a value of zero
indicating an error (e.g., `convert_utf8_to_utf16le`). They are well suited in the
scenario where you expect the input to be valid most of the time.
```cpp
/**
* Convert Latin1 string into UTF-8 string.
*
* This function is suitable to work with inputs from untrusted sources.
*
* @param input the Latin1 string to convert
* @param length the length of the string in bytes
* @param utf8_output the pointer to buffer that can hold conversion result
* @return the number of written char; 0 if conversion is not possible
*/
simdutf_warn_unused size_t convert_latin1_to_utf8(const char * input, size_t length, char* utf8_output) noexcept;
/**
* Convert Latin1 string into UTF-8 string with output limit.
*
* This function is suitable to work with inputs from untrusted sources.
*
* @param input the Latin1 string to convert
* @param length the length of the string in bytes
* @param utf8_output the pointer to buffer that can hold conversion result
* @param utf8_len the maximum output length
* @return the number of written char; 0 if conversion is not possible
*/
simdutf_warn_unused size_t convert_latin1_to_utf8_safe(const char * input, size_t length, char* utf8_output, size_t utf8_len) noexcept;
/**
* Using native endianness, convert a Latin1 string into a UTF-16 string.
*
* @param input the Latin1 string to convert
* @param length the length of the string in bytes
* @param utf16_buffer the pointer to buffer that can hold conversion result
* @return the number of written char16_t.
*/
simdutf_warn_unused size_t convert_latin1_to_utf16(const char * input, size_t length, char16_t* utf16_output) noexcept;
/**
* Convert possibly Latin1 string into UTF-16LE string.
*
* This function is suitable to work with inputs from untrusted sources.
*
* @param input the Latin1 string to convert
* @param length the length of the string in bytes
* @param utf16_buffer the pointer to buffer that can hold conversion result
* @return the number of written char16_t; 0 if conversion is not possible
*/
simdutf_warn_unused size_t convert_latin1_to_utf16le(const char * input, size_t length, char16_t* utf16_output) noexcept;
/**
* Convert Latin1 string into UTF-16BE string.
*
* This function is suitable to work with inputs from untrusted sources.
*
* @param input the Latin1 string to convert
* @param length the length of the string in bytes
* @param utf16_buffer the pointer to buffer that can hold conversion result
* @return the number of written char16_t; 0 if conversion is not possible
*/
simdutf_warn_unused size_t convert_latin1_to_utf16be(const char * input, size_t length, char16_t* utf16_output) noexcept;
/**
* Convert Latin1 string into UTF-32 string.
*
* This function is suitable to work with inputs from untrusted sources.
*
* @param input the Latin1 string to convert
* @param length the length of the string in bytes
* @param utf32_buffer the pointer to buffer that can hold conversion result
* @return the number of written char32_t; 0 if conversion is not possible
*/
simdutf_warn_unused size_t convert_latin1_to_utf32(const char * input, size_t length, char32_t* utf32_buffer) noexcept;
/**
* Convert possibly broken UTF-8 string into Latin1 string.
* If the string cannot be represented as Latin1, an error
* code is returned.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* @param input the UTF-8 string to convert
* @param length the length of the string in bytes
* @param latin1_output the pointer to buffer that can hold conversion result
* @return the number of written char; 0 if the input was not valid UTF-8 string or if it cannot be represented as Latin1
*/
simdutf_warn_unused size_t convert_utf8_to_latin1(const char * input, size_t length, char* latin1_output) noexcept;
/**
* Using native endianness; Convert possibly broken UTF-8 string into a UTF-16 string.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* @param input the UTF-8 string to convert
* @param length the length of the string in bytes
* @param utf16_buffer the pointer to buffer that can hold conversion result
* @return the number of written char16_t; 0 if the input was not valid UTF-8 string
*/
simdutf_warn_unused size_t convert_utf8_to_utf16(const char * input, size_t length, char16_t* utf16_output) noexcept;
/**
* Convert possibly broken UTF-8 string into UTF-16LE string.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* @param input the UTF-8 string to convert
* @param length the length of the string in bytes
* @param utf16_buffer the pointer to buffer that can hold conversion result
* @return the number of written char16_t; 0 if the input was not valid UTF-8 string
*/
simdutf_warn_unused size_t convert_utf8_to_utf16le(const char * input, size_t length, char16_t* utf16_output) noexcept;
/**
* Convert possibly broken UTF-8 string into UTF-16BE string.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* @param input the UTF-8 string to convert
* @param length the length of the string in bytes
* @param utf16_buffer the pointer to buffer that can hold conversion result
* @return the number of written char16_t; 0 if the input was not valid UTF-8 string
*/
simdutf_warn_unused size_t convert_utf8_to_utf16be(const char * input, size_t length, char16_t* utf16_output) noexcept;
/**
* Convert possibly broken UTF-8 string into UTF-32 string.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* @param input the UTF-8 string to convert
* @param length the length of the string in bytes
* @param utf32_buffer the pointer to buffer that can hold conversion result
* @return the number of written char32_t; 0 if the input was not valid UTF-8 string
*/
simdutf_warn_unused size_t convert_utf8_to_utf32(const char * input, size_t length, char32_t* utf32_output) noexcept;
/**
* Using native endianness, convert possibly broken UTF-16 string into UTF-8
* string.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* This function is not BOM-aware.
*
* @param input the UTF-16 string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @param utf8_buffer the pointer to buffer that can hold conversion result
* @return number of written code units; 0 if input is not a valid UTF-16LE
* string
*/
simdutf_warn_unused size_t convert_utf16_to_utf8(const char16_t *input,
size_t length,
char *utf8_buffer) noexcept;
/**
* Using native endianness, convert possibly broken UTF-16 string into UTF-8
* string with output limit.
*
* We write as many characters as possible into the output buffer,
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* This function is not BOM-aware.
*
*
* @param input the UTF-16 string to convert
* @param length the length of the string in 16-bit code units (char16_t)
* @param utf8_output the pointer to buffer that can hold conversion result
* @param utf8_len the maximum output length
* @return the number of written char; 0 if conversion is not possible
*/
simdutf_warn_unused size_t
convert_utf16_to_utf8_safe(const char16_t *input, size_t length, char *utf8_output,
size_t utf8_len) noexcept;
/**
* Using native endianness, convert possibly broken UTF-16 string into Latin1 string.
* If the string cannot be represented as Latin1, an error
* is returned.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* This function is not BOM-aware.
*
* @param input the UTF-16 string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @param latin1_buffer the pointer to buffer that can hold conversion result
* @return number of written code units; 0 if input is not a valid UTF-16 string or if it cannot be represented as Latin1
*/
simdutf_warn_unused size_t convert_utf16_to_latin1(const char16_t * input, size_t length, char* latin1_buffer) noexcept;
/**
* Convert possibly broken UTF-16LE string into Latin1 string.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* This function is not BOM-aware.
*
* @param input the UTF-16LE string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @param latin1_buffer the pointer to buffer that can hold conversion result
* @return number of written code units; 0 if input is not a valid UTF-16LE string or if it cannot be represented as Latin1
*/
simdutf_warn_unused size_t convert_utf16le_to_latin1(const char16_t * input, size_t length, char* latin1_buffer) noexcept;
/**
* Convert possibly broken UTF-16BE string into Latin1 string.
* If the string cannot be represented as Latin1, an error
* is returned.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* This function is not BOM-aware.
*
* @param input the UTF-16BE string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @param latin1_buffer the pointer to buffer that can hold conversion result
* @return number of written code units; 0 if input is not a valid UTF-16BE string or if it cannot be represented as Latin1
*/
simdutf_warn_unused size_t convert_utf16be_to_latin1(const char16_t * input, size_t length, char* latin1_buffer) noexcept;
/**
* Convert possibly broken UTF-16LE string into UTF-8 string.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* This function is not BOM-aware.
*
* @param input the UTF-16LE string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @param utf8_buffer the pointer to buffer that can hold conversion result
* @return number of written code units; 0 if input is not a valid UTF-16LE string
*/
simdutf_warn_unused size_t convert_utf16le_to_utf8(const char16_t * input, size_t length, char* utf8_buffer) noexcept;
/**
* Convert possibly broken UTF-16BE string into UTF-8 string.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* This function is not BOM-aware.
*
* @param input the UTF-16BE string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @param utf8_buffer the pointer to buffer that can hold conversion result
* @return number of written code units; 0 if input is not a valid UTF-16LE string
*/
simdutf_warn_unused size_t convert_utf16be_to_utf8(const char16_t * input, size_t length, char* utf8_buffer) noexcept;
/**
* Convert possibly broken UTF-32 string into Latin1 string.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* This function is not BOM-aware.
*
* @param input the UTF-32 string to convert
* @param length the length of the string in 4-byte code units (char32_t)
* @param latin1_buffer the pointer to buffer that can hold conversion result
* @return number of written code units; 0 if input is not a valid UTF-32 string or if it cannot be represented as Latin1
*/
simdutf_warn_unused size_t convert_utf32_to_latin1(const char32_t * input, size_t length, char* latin1_buffer) noexcept;
/**
* Convert possibly broken UTF-32 string into UTF-8 string.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* This function is not BOM-aware.
*
* @param input the UTF-32 string to convert
* @param length the length of the string in 4-byte code units (char32_t)
* @param utf8_buffer the pointer to buffer that can hold conversion result
* @return number of written code units; 0 if input is not a valid UTF-32 string
*/
simdutf_warn_unused size_t convert_utf32_to_utf8(const char32_t * input, size_t length, char* utf8_buffer) noexcept;
/**
* Using native endianness; Convert possibly broken UTF-32 string into a UTF-16 string.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* This function is not BOM-aware.
*
* @param input the UTF-32 string to convert
* @param length the length of the string in 4-byte code units (char32_t)
* @param utf16_buffer the pointer to buffer that can hold conversion result
* @return number of written code units; 0 if input is not a valid UTF-32 string
*/
simdutf_warn_unused size_t convert_utf32_to_utf16(const char32_t * input, size_t length, char16_t* utf16_buffer) noexcept;
/**
* Convert possibly broken UTF-32 string into UTF-16LE string.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* This function is not BOM-aware.
*
* @param input the UTF-32 string to convert
* @param length the length of the string in 4-byte code units (char32_t)
* @param utf16_buffer the pointer to buffer that can hold conversion result
* @return number of written code units; 0 if input is not a valid UTF-32 string
*/
simdutf_warn_unused size_t convert_utf32_to_utf16le(const char32_t * input, size_t length, char16_t* utf16_buffer) noexcept;
/**
* Convert possibly broken UTF-32 string into UTF-16BE string.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* This function is not BOM-aware.
*
* @param input the UTF-32 string to convert
* @param length the length of the string in 4-byte code units (char32_t)
* @param utf16_buffer the pointer to buffer that can hold conversion result
* @return number of written code units; 0 if input is not a valid UTF-32 string
*/
simdutf_warn_unused size_t convert_utf32_to_utf16be(const char32_t * input, size_t length, char16_t* utf16_buffer) noexcept;
/**
* Using native endianness; Convert possibly broken UTF-16 string into UTF-32 string.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* This function is not BOM-aware.
*
* @param input the UTF-16 string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @param utf32_buffer the pointer to buffer that can hold conversion result
* @return number of written code units; 0 if input is not a valid UTF-16LE string
*/
simdutf_warn_unused size_t convert_utf16_to_utf32(const char16_t * input, size_t length, char32_t* utf32_buffer) noexcept;
/**
* Convert possibly broken UTF-16LE string into UTF-32 string.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* This function is not BOM-aware.
*
* @param input the UTF-16LE string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @param utf32_buffer the pointer to buffer that can hold conversion result
* @return number of written code units; 0 if input is not a valid UTF-16LE string
*/
simdutf_warn_unused size_t convert_utf16le_to_utf32(const char16_t * input, size_t length, char32_t* utf32_buffer) noexcept;
/**
* Convert possibly broken UTF-16BE string into UTF-32 string.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* This function is not BOM-aware.
*
* @param input the UTF-16BE string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @param utf32_buffer the pointer to buffer that can hold conversion result
* @return number of written code units; 0 if input is not a valid UTF-16LE string
*/
simdutf_warn_unused size_t convert_utf16be_to_utf32(const char16_t * input, size_t length, char32_t* utf32_buffer) noexcept;
```
In some cases, you need to transcode UTF-8 or UTF-16 inputs, but you may have a truncated
string, meaning that the last character might be incomplete. In such cases, we recommend
trimming the end of your input so you do not encounter an error.
```cpp
/**
* Given a valid UTF-8 string having a possibly truncated last character,
* this function checks the end of string. If the last character is truncated (or partial),
* then it returns a shorter length (shorter by 1 to 3 bytes) so that the short UTF-8
* strings only contain complete characters. If there is no truncated character,
* the original length is returned.
*
* This function assumes that the input string is valid UTF-8, but possibly truncated.
*
* @param input the UTF-8 string to process
* @param length the length of the string in bytes
* @return the length of the string in bytes, possibly shorter by 1 to 3 bytes
*/
simdutf_warn_unused size_t trim_partial_utf8(const char *input, size_t length);
/**
* Given a valid UTF-16BE string having a possibly truncated last character,
* this function checks the end of string. If the last character is truncated (or partial),
* then it returns a shorter length (shorter by 1 unit) so that the short UTF-16BE
* strings only contain complete characters. If there is no truncated character,
* the original length is returned.
*
* This function assumes that the input string is valid UTF-16BE, but possibly truncated.
*
* @param input the UTF-16BE string to process
* @param length the length of the string in bytes
* @return the length of the string in bytes, possibly shorter by 1 unit
*/
simdutf_warn_unused size_t trim_partial_utf16be(const char16_t* input, size_t length);
/**
* Given a valid UTF-16LE string having a possibly truncated last character,
* this function checks the end of string. If the last character is truncated (or partial),
* then it returns a shorter length (shorter by 1 unit) so that the short UTF-16LE
* strings only contain complete characters. If there is no truncated character,
* the original length is returned.
*
* This function assumes that the input string is valid UTF-16LE, but possibly truncated.
*
* @param input the UTF-16LE string to process
* @param length the length of the string in bytes
* @return the length of the string in unit, possibly shorter by 1 unit
*/
simdutf_warn_unused size_t trim_partial_utf16le(const char16_t* input, size_t length);
/**
* Given a valid UTF-16 string having a possibly truncated last character,
* this function checks the end of string. If the last character is truncated (or partial),
* then it returns a shorter length (shorter by 1 unit) so that the short UTF-16
* strings only contain complete characters. If there is no truncated character,
* the original length is returned.
*
* This function assumes that the input string is valid UTF-16, but possibly truncated.
* We use the native endianness.
*
* @param input the UTF-16 string to process
* @param length the length of the string in bytes
* @return the length of the string in unit, possibly shorter by 1 unit
*/
simdutf_warn_unused size_t trim_partial_utf16(const char16_t* input, size_t length);
```
You may use these `trim_` functions to decode inputs piece by piece, as in the following
examples. First a case where you want to decode a UTF-8 strings in two steps:
```cpp
const char unicode[] = "\xc3\xa9\x63ole d'\xc3\xa9t\xc3\xa9";
// suppose you want to decode only the start of this string.
size_t length = 10;
// Picking 10 bytes is problematic because we might end up in the middle of a
// code point. But we can rewind to the previous code point.
length = simdutf::trim_partial_utf8(unicode, length);
// Now we can transcode safely
size_t budget_utf16 = simdutf::utf16_length_from_utf8(unicode, length);
std::unique_ptr<char16_t[]> utf16{new char16_t[budget_utf16]};
size_t utf16words =
simdutf::convert_utf8_to_utf16le(unicode, length, utf16.get());
// We can then transcode the next batch
const char * next = unicode + length;
size_t next_length = sizeof(unicode) - length;
size_t next_budget_utf16 = simdutf::utf16_length_from_utf8(next, next_length);
std::unique_ptr<char16_t[]> next_utf16{new char16_t[next_budget_utf16]};
size_t next_utf16words =
simdutf::convert_utf8_to_utf16le(next, next_length, next_utf16.get());
```
You can use the same approach with UTF-16:
```cpp // We have three sequences of surrogate pairs (UTF-16).
const char16_t unicode[] = u"\x3cd8\x10df\x3cd8\x10df\x3cd8\x10df";
// suppose you want to decode only the start of this string.
size_t length = 3;
// Picking 3 units is problematic because we might end up in the middle of a
// surrogate pair. But we can rewind to the previous code point.
length = simdutf::trim_partial_utf16(unicode, length);
// Now we can transcode safely
size_t budget_utf8 = simdutf::utf8_length_from_utf16(unicode, length);
std::unique_ptr<char[]> utf8{new char[budget_utf8]};
size_t utf8words =
simdutf::convert_utf16_to_utf8(unicode, length, utf8.get());
// We can then transcode the next batch
const char16_t * next = unicode + length;
size_t next_length = 6 - length;
size_t next_budget_utf8 = simdutf::utf8_length_from_utf16(next, next_length);
std::unique_ptr<char[]> next_utf8{new char[next_budget_utf8]};
size_t next_utf8words =
simdutf::convert_utf16_to_utf8(next, next_length, next_utf8.get());
```
We have more advanced conversion functions which output a `simdutf::result` structure with
an indication of the error type and a `count` entry (e.g., `convert_utf8_to_utf16le_with_errors`).
They are well suited when you expect that there might be errors in the input that require
further investigation. The `count` field contains the location of the error in the input in code units,
if there is an error, or otherwise the number of code units written. You may use these functions as follows:
```cpp
// this UTF-8 string has a bad byte at index 5
std::string bad_utf8 = "\xc3\xa9\xc3\xa9\x20\xff\xc3\xa9";
size_t budget_utf16 = simdutf::utf16_length_from_utf8(bad_utf8.data(), bad_utf8.size());
std::unique_ptr<char16_t[]> utf16{new char16_t[budget_utf16]};
simdutf::result res = simdutf::convert_utf8_to_utf16_with_errors(bad_utf8.data(), bad_utf8.size(), utf16.get());
if(res.error != simdutf::error_code::SUCCESS) {
std::cerr << "error at index " << res.count << std::endl;
}
// the following will be successful
res = simdutf::convert_utf8_to_utf16_with_errors(bad_utf8.data(), res.count, utf16.get());
if(res.error == simdutf::error_code::SUCCESS) {
std::cerr << "we have transcoded " << res.count << " characters" << std::endl;
}
```
We have several transcoding functions returning `simdutf::error` results:
```cpp
/**
* Convert possibly broken UTF-8 string into Latin1 string with errors.
* If the string cannot be represented as Latin1, an error
* code is returned.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* @param input the UTF-8 string to convert
* @param length the length of the string in bytes
* @param latin1_output the pointer to buffer that can hold conversion result
* @return a result pair struct (of type simdutf::result containing the two fields error and count) with an error code and either position of the error (in the input in code units) if any, or the number of code units validated if successful.
*/
simdutf_warn_unused result convert_utf8_to_latin1_with_errors(const char * input, size_t length, char* latin1_output) noexcept;
/**
* Convert possibly broken UTF-16LE string into Latin1 string.
* If the string cannot be represented as Latin1, an error
* is returned.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
* This function is not BOM-aware.
*
* @param input the UTF-16LE string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @param latin1_buffer the pointer to buffer that can hold conversion result
* @return a result pair struct (of type simdutf::result containing the two fields error and count) with an error code and either position of the error (in the input in code units) if any, or the number of char written if successful.
*/
simdutf_warn_unused result convert_utf16le_to_latin1_with_errors(const char16_t * input, size_t length, char* latin1_buffer) noexcept;
/**
* Convert possibly broken UTF-16BE string into Latin1 string.
* If the string cannot be represented as Latin1, an error
* is returned.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
* This function is not BOM-aware.
*
* @param input the UTF-16BE string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @param latin1_buffer the pointer to buffer that can hold conversion result
* @return a result pair struct (of type simdutf::result containing the two fields error and count) with an error code and either position of the error (in the input in code units) if any, or the number of char written if successful.
*/
simdutf_warn_unused result convert_utf16be_to_latin1_with_errors(const char16_t * input, size_t length, char* latin1_buffer) noexcept;
/**
* Using native endianness, convert possibly broken UTF-16 string into Latin1 string.
* If the string cannot be represented as Latin1, an error
* is returned.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
* This function is not BOM-aware.
*
* @param input the UTF-16 string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @param latin1_buffer the pointer to buffer that can hold conversion result
* @return a result pair struct (of type simdutf::result containing the two fields error and count) with an error code and either position of the error (in the input in code units) if any, or the number of char written if successful.
*/
simdutf_warn_unused result convert_utf16_to_latin1_with_errors(const char16_t * input, size_t length, char* latin1_buffer) noexcept;
/**
* Using native endianness; Convert possibly broken UTF-8 string into UTF-16
* string and stop on error.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* @param input the UTF-8 string to convert
* @param length the length of the string in bytes
* @param utf16_buffer the pointer to buffer that can hold conversion result
* @return a result pair struct (of type simdutf::result containing the two fields error and count) with an error code and either position of the error (in the input in code units) if any, or the number of char16_t written if successful.
*/
simdutf_warn_unused result convert_utf8_to_utf16_with_errors(const char * input, size_t length, char16_t* utf16_output) noexcept;
/**
* Convert possibly broken UTF-8 string into UTF-16LE string and stop on error.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* @param input the UTF-8 string to convert
* @param length the length of the string in bytes
* @param utf16_buffer the pointer to buffer that can hold conversion result
* @return a result pair struct (of type simdutf::result containing the two fields error and count) with an error code and either position of the error (in the input in code units) if any, or the number of char16_t written if successful.
*/
simdutf_warn_unused result convert_utf8_to_utf16le_with_errors(const char * input, size_t length, char16_t* utf16_output) noexcept;
/**
* Convert possibly broken UTF-8 string into UTF-16BE string and stop on error.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* @param input the UTF-8 string to convert
* @param length the length of the string in bytes
* @param utf16_buffer the pointer to buffer that can hold conversion result
* @return a result pair struct (of type simdutf::result containing the two fields error and count) with an error code and either position of the error (in the input in code units) if any, or the number of char16_t written if successful.
*/
simdutf_warn_unused result convert_utf8_to_utf16be_with_errors(const char * input, size_t length, char16_t* utf16_output) noexcept;
/**
* Convert possibly broken UTF-8 string into UTF-32 string and stop on error.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* @param input the UTF-8 string to convert
* @param length the length of the string in bytes
* @param utf32_buffer the pointer to buffer that can hold conversion result
* @return a result pair struct (of type simdutf::result containing the two fields error and count) with an error code and either position of the error (in the input in code units) if any, or the number of char32_t written if successful.
*/
simdutf_warn_unused result convert_utf8_to_utf32_with_errors(const char * input, size_t length, char32_t* utf32_output) noexcept;
/**
* Convert possibly broken UTF-16LE string into UTF-8 string and stop on error.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* This function is not BOM-aware.
*
* @param input the UTF-16LE string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @param utf8_buffer the pointer to buffer that can hold conversion result
* @return a result pair struct (of type simdutf::result containing the two fields error and count) with an error code and either position of the error (in the input in code units) if any, or the number of char written if successful.
*/
simdutf_warn_unused result convert_utf16le_to_utf8_with_errors(const char16_t * input, size_t length, char* utf8_buffer) noexcept;
/**
* Convert possibly broken UTF-16BE string into UTF-8 string and stop on error.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* This function is not BOM-aware.
*
* @param input the UTF-16BE string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @param utf8_buffer the pointer to buffer that can hold conversion result
* @return a result pair struct (of type simdutf::result containing the two fields error and count) with an error code and either position of the error (in the input in code units) if any, or the number of char written if successful.
*/
simdutf_warn_unused result convert_utf16be_to_utf8_with_errors(const char16_t * input, size_t length, char* utf8_buffer) noexcept;
/**
* Convert possibly broken UTF-32 string into Latin1 string and stop on error.
* If the string cannot be represented as Latin1, an error is returned.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* This function is not BOM-aware.
*
* @param input the UTF-32 string to convert
* @param length the length of the string in 4-byte code units (char32_t)
* @param latin1_buffer the pointer to buffer that can hold conversion result
* @return a result pair struct (of type simdutf::result containing the two fields error and count) with an error code and either position of the error (in the input in code units) if any, or the number of char written if successful.
*/
simdutf_warn_unused result convert_utf32_to_latin1_with_errors(const char32_t * input, size_t length, char* latin1_buffer) noexcept;
/**
* Convert possibly broken UTF-32 string into UTF-8 string and stop on error.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* This function is not BOM-aware.
*
* @param input the UTF-32 string to convert
* @param length the length of the string in 4-byte code units (char32_t)
* @param utf8_buffer the pointer to buffer that can hold conversion result
* @return a result pair struct (of type simdutf::result containing the two fields error and count) with an error code and either position of the error (in the input in code units) if any, or the number of char written if successful.
*/
simdutf_warn_unused result convert_utf32_to_utf8_with_errors(const char32_t * input, size_t length, char* utf8_buffer) noexcept;
/**
* Using native endianness; Convert possibly broken UTF-32 string into UTF-16
* string and stop on error.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* This function is not BOM-aware.
*
* @param input the UTF-32 string to convert
* @param length the length of the string in 4-byte code units (char32_t)
* @param utf16_buffer the pointer to buffer that can hold conversion result
* @return a result pair struct (of type simdutf::result containing the two fields error and count) with an error code and either position of the error (in the input in code units) if any, or the number of char16_t written if successful.
*/
simdutf_warn_unused result convert_utf32_to_utf16_with_errors(const char32_t * input, size_t length, char16_t* utf16_buffer) noexcept;
/**
* Convert possibly broken UTF-32 string into UTF-16LE string and stop on error.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* This function is not BOM-aware.
*
* @param input the UTF-32 string to convert
* @param length the length of the string in 4-byte code units (char32_t)
* @param utf16_buffer the pointer to buffer that can hold conversion result
* @return a result pair struct (of type simdutf::result containing the two fields error and count) with an error code and either position of the error (in the input in code units) if any, or the number of char16_t written if successful.
*/
simdutf_warn_unused result convert_utf32_to_utf16le_with_errors(const char32_t * input, size_t length, char16_t* utf16_buffer) noexcept;
/**
* Convert possibly broken UTF-32 string into UTF-16BE string and stop on error.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* This function is not BOM-aware.
*
* @param input the UTF-32 string to convert
* @param length the length of the string in 4-byte code units (char32_t)
* @param utf16_buffer the pointer to buffer that can hold conversion result
* @return a result pair struct (of type simdutf::result containing the two fields error and count) with an error code and either position of the error (in the input in code units) if any, or the number of char16_t written if successful.
*/
simdutf_warn_unused result convert_utf32_to_utf16be_with_errors(const char32_t * input, size_t length, char16_t* utf16_buffer) noexcept;
/**
* Using native endianness; Convert possibly broken UTF-16 string into
* UTF-32 string and stop on error.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* This function is not BOM-aware.
*
* @param input the UTF-16 string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @param utf32_buffer the pointer to buffer that can hold conversion result
* @return a result pair struct (of type simdutf::result containing the two fields error and count) with an error code and either position of the error (in the input in code units) if any, or the number of char32_t written if successful.
*/
simdutf_warn_unused result convert_utf16_to_utf32_with_errors(const char16_t * input, size_t length, char32_t* utf32_buffer) noexcept;
/**
* Convert possibly broken UTF-16LE string into UTF-32 string and stop on error.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* This function is not BOM-aware.
*
* @param input the UTF-16LE string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @param utf32_buffer the pointer to buffer that can hold conversion result
* @return a result pair struct (of type simdutf::result containing the two fields error and count) with an error code and either position of the error (in the input in code units) if any, or the number of char32_t written if successful.
*/
simdutf_warn_unused result convert_utf16le_to_utf32_with_errors(const char16_t * input, size_t length, char32_t* utf32_buffer) noexcept;
/**
* Convert possibly broken UTF-16BE string into UTF-32 string and stop on error.
*
* During the conversion also validation of the input string is done.
* This function is suitable to work with inputs from untrusted sources.
*
* This function is not BOM-aware.
*
* @param input the UTF-16BE string to convert
* @param length the length of the string in 2-byte code units (char16_t)
* @param utf32_buffer the pointer to buffer that can hold conversion result
* @return a result pair struct (of type simdutf::result containing the two fields error and count) with an error code and either position of the error (in the input in code units) if any, or the number of char32_t written if successful.
*/
simdutf_warn_unused result convert_utf16be_to_utf32_with_errors(const char16_t * input, size_t length, char32_t* utf32_buffer) noexcept;
```
If you have a UTF-16 input, you may change its endianness with a fast function.
```cpp
/**
* Change the endianness of the input. Can be used to go from UTF-16LE to UTF-16BE or
* from UTF-16BE to UTF-16LE.
*
* This function does not validate the input.
*
* This function is not BOM-aware.
*
* @param input the UTF-16 string to process
* @param length the length of the string in 2-byte code units (char16_t)
* @param output the pointer to a buffer that can hold the conversion result
*/
void change_endianness_utf16(const char16_t * input, size_t length, char16_t * output) noexcept;
```
Base64
-----
The WHATWG (Web Hypertext Application Technology Working Group) defines a "forgiving" base64 decoding algorithm in its Infra Standard, which is used in web contexts like the JavaScript atob() function. This algorithm is more lenient than strict RFC 4648 base64, primarily to handle common web data variations. It ignores all ASCII whitespace (spaces, tabs, newlines, etc.), allows omitting padding characters (=), and decodes inputs as long as they meet certain length and character validity rules. However, it still rejects inputs that could lead to ambiguous or incomplete byte formation.
We also converting from [WHATWG forgiving-base64](https://infra.spec.whatwg.org/#forgiving-base64-decode) to binary, and back. In particular, you can convert base64 inputs which contain ASCII spaces (' ', '\t', '\n', '\r', '\f') to binary. We also support the base64 URL encoding alternative. These functions are part of the Node.js JavaScript runtime: in particular `atob` in Node.js relies on simdutf.
The key steps in this algorithm are:
- Remove all whitespace from the input string.
- If the resulting string's length is a multiple of 4 and it ends with one or two '=' characters, remove those '=' from the end (treating them as optional padding).
- If the length (after any padding removal) modulo 4 equals 1, the input is invalid— this prevents cases where the bit count wouldn't align properly to form whole bytes.
- Check that all remaining characters are valid base64 symbols (A-Z, a-z, 0-9, +, /, or =); otherwise, invalid.
- Decode by converting each character to its 6-bit value, concatenating the bits, and grouping them into 8-bit bytes. At the end, if there are leftover bits (12 or 18), form as many full bytes as possible and discard the trailing bits (4 or 2, respectively), assuming they are padding zeros.
This forgiving approach makes base64 decoding robust for web use, but it enforces rules to avoid data corruption.
The conversion of binary data to base64 always succeeds and is relatively simple. Suppose
that you have an original input of binary data `source` (e.g., `std::vector<char>`).
```cpp
std::vector<char> buffer(simdutf::base64_length_from_binary(source.size()));
simdutf::binary_to_base64(source.data(), source.size(), buffer.data());
```
Decoding base64 requires validation and, thus, error handling. Furthermore, because
we prune ASCII spaces, we may need to adjust the result size afterward.
```cpp
std::vector<char> buffer(simdutf::maximal_binary_length_from_base64(base64.data(), base64.size()));
simdutf::result r = simdutf::base64_to_binary(base64.data(), base64.size(), buffer.data());
if(r.error) {
// We have some error, r.count tells you where the error was encountered in the input if
// the error is INVALID_BASE64_CHARACTER. If the error is BASE64_INPUT_REMAINDER, then
// a single valid base64 character remained, and r.count contains the number of bytes decoded.
} else {
buffer.resize(r.count); // resize the buffer according to actual number of bytes
}
```
Let us consider concrete examples. Take the following strings:
`" A A "`, `" A A G A / v 8 "`, `" A A G A / v 8 = "`, `" A A G A / v 8 = = "`.
They are all valid WHATWG base64 inputs, except for the last one.
- The first string, `" A A "`, becomes "AA" after whitespace removal. Its length is 2, and 2 % 4 = 2 (not 1), so it's valid. Decoding: 'A' is 000000 and 'A' is 000000, giving 12 bits (000000000000). Form one byte from the first 8 bits (00000000 = 0x00) and discard the last 4 bits (0000). Result: a single byte value of 0.
- The second string, `" A A G A / v 8 "`, becomes "AAGA/v8" (length 7, 7 % 4 = 3, not 1—valid). Decoding the 42 bits yields the byte sequence 0x00, 0x01, 0x80, 0xFE, 0xFF (as you noted; the process groups full 24-bit chunks into three bytes each, then handles the remaining 18 bits as two bytes, discarding the last 2 bits).
- The third string, `" A A G A / v 8 = "`, becomes "AAGA/v8=" (length 8, 8 % 4 = 0). It ends with one '=', so remove it, leaving "AAGA/v8" (same as the second example). Valid, and decodes to the same byte sequence: 0x00, 0x01, 0x80, 0xFE, 0xFF.
- The fourth string, `" A A G A / v 8 = = "`, becomes "AAGA/v8==" (length 9, 9 % 4 = 1). The length isn't a multiple of 4, so the algorithm doesn't remove the trailing '=='. Since the length modulo 4 is 1, it's invalid. This rule exists because a remainder of 1 would leave only 6 leftover bits after full bytes, which can't form a complete byte (unlike remainders of 2 or 3, which leave 12 or 18 bits and allow discarding 4 or 2 bits). Adding extra '=' here disrupts the expected alignment without qualifying for padding removal.
Let us process them with actual code.
```cpp
std::vector<std::string> sources = {
" A A ", " A A G A / v 8 ", " A A G A / v 8 = ", " A A G A / v 8 = = "};
std::vector<std::vector<uint8_t>> expected = {
{0}, {0, 0x1, 0x80, 0xfe, 0xff}, {0, 0x1, 0x80, 0xfe, 0xff}, {}}; // last one is in error
for(size_t i = 0; i < sources.size(); i++) {
const std::string &source = sources[i];
std::cout << "source: '" << source << "'" << std::endl;
// allocate enough memory for the maximal binary length
std::vector<uint8_t> buffer(simdutf::maximal_binary_length_from_base64(
source.data(), source.size()));
// convert to binary and check for errors
simdutf::result r = simdutf::base64_to_binary(
source.data(), source.size(), (char*)buffer.data());
if(r.error != simdutf::error_code::SUCCESS) {
// We have that expected[i].empty().
std::cout << "output: error" << std::endl;
} else {
buffer.resize(r.count); // in case of success, r.count contains the output length
// We have that buffer == expected[i]
std::cout << "output: " << r.count << " bytes" << std::endl;
}
}
```
This code should print the following:
```
source: ' A A '
output: 1 bytes
source: ' A A G A / v 8 '
output: 5 bytes
source: ' A A G A / v 8 = '
output: 5 bytes
source: ' A A G A / v 8 = = '
output: error
```
As you can see, the result is as expected.
In some instances, you may want to limit the size of the output further when decoding base64.
For this purpose, you may use the `base64_to_binary_safe` functions. The functions may also
be useful if you seek to decode the input into segments having a maximal capacity.
Another benefit of the `base64_to_binary_safe` functions is that they inform you
about how much data was written to the output buffer, even when there is a fatal
error.
This number might not be 'maximal': our fast functions may leave some data that could
have been decoded prior to a bad character undecoded. With the
`base64_to_binary_safe` function, you also have the option of requesting that as much
of the data as possible is decoded despite the error by setting the `decode_up_to_bad_char`
parameter to true (it defaults to false for best performance).
```cpp
size_t len = 72; // for simplicity we chose len divisible by 3
std::vector<char> base64(len, 'a'); // we want to decode 'aaaaa....'
std::vector<char> back((len + 3) / 4 * 3);
size_t limited_length = back.size() / 2; // Intentionally too small
// We proceed to decode half:
simdutf::result r = simdutf::base64_to_binary_safe(
base64.data(), base64.size(), back.data(), limited_length);
assert(r.error == simdutf::error_code::OUTPUT_BUFFER_TOO_SMALL);
// We decoded r.count base64 8-bit units to limited_length bytes
// Now let us decode the rest !!!
//
// We have read up to r.count in the input buffer and we have
// produced limited_length bytes.
//
size_t input_index = r.count;
size_t limited_length2 = back.size();
r = simdutf::base64_to_binary_safe(base64.data() + input_index,
base64.size() - input_index,
back.data(), limited_length2);
assert(r.error == simdutf::error_code::SUCCESS);
// We decoded r.count base64 8-bit units to limited_length2 bytes
// We are done
assert(limited_length2 + limited_length == (len + 3) / 4 * 3);
```
We can repeat our previous examples with the various spaced strings using
`base64_to_binary_safe`. It works much the same except that the convention
for the content of `result.count` differs. The output size is stored
by reference in the output length parameter.
```cpp
std::vector<std::string> sources = {
" A A ", " A A G A / v 8 ", " A A G A / v 8 = ", " A A G A / v 8 = = "};
std::vector<std::vector<uint8_t>> expected = {
{0}, {0, 0x1, 0x80, 0xfe, 0xff}, {0, 0x1, 0x80, 0xfe, 0xff}, {}}; // last one is in error
for(size_t i = 0; i < sources.size(); i++) {
const std::string &source = sources[i];
std::cout << "source: '" << source << "'" << std::endl;
// allocate enough memory for the maximal binary length
std::vector<uint8_t> buffer(simdutf::maximal_binary_length_from_base64(
source.data(), source.size()));
// convert to binary and check for errors
size_t output_length = buffer.size();
simdutf::result r = simdutf::base64_to_binary_safe(
source.data(), source.size(), (char*)buffer.data(), output_length);
if(r.error != simdutf::error_code::SUCCESS) {
// We have expected[i].empty()
std::cout << "output: error" << std::endl;
} else {
buffer.resize(output_length); // in case of success, output_length contains the output length
// We have buffer == expected[i])
std::cout << "output: " << output_length << " bytes" << std::endl;
std::cout << "input (consumed): " << r.count << " bytes" << std::endl;
}
```
This code should output the following:
```
source: ' A A '
output: 1 bytes
input (consumed): 8 bytes
source: ' A A G A / v 8 '
output: 5 bytes
input (consumed): 23 bytes
source: ' A A G A / v 8 = '
output: 5 bytes
input (consumed): 26 bytes
source: ' A A G A / v 8 = = '
output: error
```
See our function specifications for more details.
In other instances, you may receive your base64 inputs in 16-bit units (e.g., from UTF-16 strings):
we have function overloads for these cases as well.
Some users may want to decode the base64 inputs in chunks, especially when doing
file or networking programming. These users should see `tools/fastbase64.cpp`, a command-line
utility designed for as an example. It reads and writes base64 files using chunks of at most
a few tens of kilobytes.
We support two conventions: `base64_default` and `base64_url`:
* The default (`base64_default`) includes the characters `+` and `/` as part of its alphabet. It also
pads the output with the padding character (`=`) so that the output is divisible by 4. Thus, we have
that the string `"Hello, World!"` is encoded to `"SGVsbG8sIFdvcmxkIQ=="` with an expression such as
`simdutf::binary_to_base64(source, size, out, simdutf::base64_default)`.
When using the default, you can omit the option parameter for simplicity:
`simdutf::binary_to_base64(source, size, out, buffer.data())`. When decoding, white space
characters are omitted as per the [WHATWG forgiving-base64](https://infra.spec.whatwg.org/#forgiving-base64-decode) standard. Further, if padding characters are present at the end of the
stream, there must be no more than two, and if there are any, the total number of characters (excluding
ASCII spaces ' ', '\t', '\n', '\r', '\f' but including padding characters) must be divisible by four.
* The URL convention (`base64_url`) uses the characters `-` and `_` as part of its alphabet. It does
not pad its output. Thus, we have that the string `"Hello, World!"` is encoded to `"SGVsbG8sIFdvcmxkIQ"` instead of `"SGVsbG8sIFdvcmxkIQ=="`. To specify the URL convention, you can pass the appropriate option to our decoding and encoding functions: e.g., `simdutf::base64_to_binary(source, size, out, simdutf::base64_url)`.
When we encounter a character that is neither an ASCII space nor a base64 character (a garbage character), we detect an error. To tolerate 'garbage' characters, you can use `base64_default_accept_garbage` or `base64_url_accept_garbage` instead of `base64_default` or `base64_url`.
Thus we follow the convention of systems such as the Node or Bun JavaScript runtimes with respect to padding. The
default base64 uses padding whereas the URL variant does not.
```JavaScript
> console.log(Buffer.from("Hello World").toString('base64'));
SGVsbG8gV29ybGQ=
undefined
> console.log(Buffer.from("Hello World").toString('base64url'));
SGVsbG8gV29ybGQ
```
This is justified as per [RFC 4648](https://www.rfc-editor.org/rfc/rfc4648):
> The pad character "=" is typically percent-encoded when used in an URI, but if the data length is known implicitly, this can be avoided by skipping the padding; see section 3.2.
Nevertheless, some users may want to use padding with the URL variant
and omit it with the default variant. These users can
'reverse' the convention by using `simdutf::base64_url | simdutf::base64_reverse_padding` or `simdutf::base64_default | simdutf::base64_reverse_padding`.
For greater convenience, you may use `simdutf::base64_default_no_padding` and
`simdutf::base64_url_with_padding`, as shorthands.
When decoding, by default we use a loose approach: the padding character may be omitted.
Advanced users may use the `last_chunk_options` parameter to use either a `strict` approach,
where precise padding must be used or an error is generated, or the `stop_before_partial`
option which discards leftover base64 characters when the padding is not appropriate.
The `stop_before_partial` option might be appropriate for streaming applications
where you expect to get part of the base64 stream.
The `strict` approach is useful if you want to have one-to-one correspondence between
the base64 code and the binary data. If the default setting is used (`last_chunk_handling_options::loose`),
then `"ZXhhZg=="`, `"ZXhhZg"`, `"ZXhhZh=="` all decode to the same binary content.
If `last_chunk_options` is set to `last_chunk_handling_options::strict`, then
decoding `"ZXhhZg=="` succeeds, but decoding `"ZXhhZg"` fails with `simdutf::error_code::BASE64_INPUT_REMAINDER` while `"ZXhhZh=="` fails with
`simdutf::error_code::BASE64_EXTRA_BITS`. If `last_chunk_options` is set to `last_chunk_handling_options::stop_before_partial`,
then decoding `"ZXhhZg"` decodes into `exa` (and `Zg` is left over).
The specification of our base64 functions is as follows:
```cpp
// base64_options are used to specify the base64 encoding options.
// ASCII spaces are ' ', '\t', '\n', '\r', '\f'
// garbage characters are characters that are not part of the base64 alphabet nor ASCII spaces.
using base64_options = uint64_t;
enum base64_options : uint64_t {
base64_default = 0, /* standard base64 format (with padding) */
base64_url = 1, /* base64url format (no padding) */
base64_default_no_padding =
base64_default |
base64_reverse_padding, /* standard base64 format without padding */
base64_url_with_padding =
base64_url | base64_reverse_padding, /* base64url with padding */
base64_default_accept_garbage =
4, /* standard base64 format accepting garbage characters, the input stops with the first '=' if any */
base64_url_accept_garbage =
5, /* base64url format accepting garbage characters, the input stops with the first '=' if any */
base64_default_or_url =
8, /* standard/base64url hybrid format (only meaningful for decoding!) */
base64_default_or_url_accept_garbage =
12, /* standard/base64url hybrid format accepting garbage characters
(only meaningful for decoding!), the input stops with the first '=' if any */
};
// last_chunk_handling_options are used to specify the handling of the last
// chunk in base64 decoding.
// https://tc39.es/proposal-arraybuffer-base64/spec/#sec-frombase64
enum last_chunk_handling_options : uint64_t {
loose = 0, /* standard base64 format, decode partial final chunk */
strict = 1, /* error when the last chunk is partial, 2 or 3 chars, and unpadded, or non-zero bit padding */
stop_before_partial = 2, /* if the last chunk is partial , ignore it (no error) */
only_full_chunks = 3 /* only decode full blocks (4 base64 characters, no padding) */
};
/**
* Provide the maximal binary length in bytes given the base64 input.
* As long as the input does not contain ignorable characters (e.g., ASCII spaces
* or linefeed characters), the result is exact. In particular, the function
* checks for padding characters.
*
* The function is fast (constant time). It checks up to two characters at
* the end of the string. The input is not otherwise validated or read.
*
* @param input the base64 input to process
* @param length the length of the base64 input in bytes
* @return maximal number of binary bytes
*/
simdutf_warn_unused size_t maximal_binary_length_from_base64(const char * input, size_t length) noexcept;
/**
* Provide the maximal binary length in bytes given the base64 input.
* As long as the input does not contain ignorable characters (e.g., ASCII spaces
* or linefeed characters), the result is exact. In particular, the function
* checks for padding characters.
*
* The function is fast (constant time). It checks up to two characters at
* the end of the string. The input is not otherwise validated or read.
*
* @param input the base64 input to process, in ASCII stored as 16-bit units
* @param length the length of the base64 input in 16-bit units
* @return maximal number of binary bytes
*/
simdutf_warn_unused size_t maximal_binary_length_from_base64(const char16_t * input, size_t length) noexcept;
/**
* Convert a base64 input to a binary output.
*
* This function follows the WHATWG forgiving-base64 format, which means that it
* will ignore any ASCII spaces in the input. You may provide a padded input
* (with one or two equal signs at the end) or an unpadded input (without any
* equal signs at the end).
*
* See https://infra.spec.whatwg.org/#forgiving-base64-decode
*
* This function will fail in case of invalid input. When last_chunk_options = loose,
* there are two possible reasons for failure: the input contains a number of
* base64 characters that when divided by 4, leaves a single remainder character
* (BASE64_INPUT_REMAINDER), or the input contains a character that is not a
* valid base64 character (INVALID_BASE64_CHARACTER).
*
* When the error is INVALID_BASE64_CHARACTER, r.count contains the index in the
* input where the invalid character was found. When the error is
* BASE64_INPUT_REMAINDER, then r.count contains the number of bytes decoded.
*
* The default option (simdutf::base64_default) expects the characters `+` and
* `/` as part of its alphabet. The URL option (simdutf::base64_url) expects the
* characters `-` and `_` as part of its alphabet.
*
* The padding (`=`) is validated if present. There may be at most two padding
* characters at the end of the input. If there are any padding characters, the
* total number of characters (excluding spaces but including padding
* characters) must be divisible by four.
*
* You should call this function with a buffer that is at least
* maximal_binary_length_from_base64(input, length) bytes long. If you fail to
* provide that much space, the function may cause a buffer overflow.
*
* Advanced users may want to tailor how the last chunk is handled. By default,
* we use a loose (forgiving) approach but we also support a strict approach
* as well as a stop_before_partial approach, as per the following proposal:
*
* https://tc39.es/proposal-arraybuffer-base64/spec/#sec-frombase64
*
* @param input the base64 string to process
* @param length the length of the string in bytes
* @param output the pointer to a buffer that can hold the conversion
* result (should be at least maximal_binary_length_from_base64(input, length)
* bytes long).
* @param options the base64 options to use, usually base64_default or
* base64_url, and base64_default by default.
* @param last_chunk_options the last chunk handling options,
* last_chunk_handling_options::loose by default
* but can also be last_chunk_handling_options::strict or
* last_chunk_handling_options::stop_before_partial.
* @return a result pair struct (of type simdutf::result containing the two
* fields error and count) with an error code and either position of the error
* (in the input in bytes) if any, or the number of bytes written if successful.
*/
simdutf_warn_unused result
base64_to_binary(const char *input, size_t length, char *output,
base64_options options = base64_default,
last_chunk_handling_options last_chunk_options = loose) noexcept;
/**
* Provide the base64 length in bytes given the length of a binary input.
*
* @param length the length of the input in bytes
* @param options the base64 options to use, can be base64_default or base64_url, is base64_default by default.
* @return number of base64 bytes
*/
simdutf_warn_unused size_t base64_length_from_binary(size_t length, base64_options options = base64_default) noexcept;
/**
* Provide the base64 length in bytes given the length of a binary input,
* taking into account line breaks.
*
* @param length the length of the input in bytes
* @param options the base64 options to use, can be base64_default or base64_url, is base64_default by default.
* @param line_length the length of lines, must be at least 4 (otherwise it is interpreted as 4),
* @return number of base64 bytes
*/
simdutf_warn_unused size_t
base64_length_from_binary_with_lines(size_t length, base64_options options, size_t line_length) noexcept;
/**
* Convert a binary input to a base64 output.
*
* The default option (simdutf::base64_default) uses the characters `+` and `/` as part of its alphabet.
* Further, it adds padding (`=`) at the end of the output to ensure that the output length is a multiple of four.
*
* The URL option (simdutf::base64_url) uses the characters `-` and `_` as part of its alphabet. No padding
* is added at the end of the output.
*
* This function always succeeds.
*
* @param input the binary to process
* @param length the length of the input in bytes
* @param output the pointer to a buffer that can hold the conversion result (should be at least base64_length_from_binary(length) bytes long)
* @param options the base64 options to use, can be base64_default or base64_url, is base64_default by default.
* @return number of written bytes, will be equal to base64_length_from_binary(length, options)
*/
size_t binary_to_base64(const char * input, size_t length, char* output, base64_options options = base64_default) noexcept;
/**
* Convert a binary input to a base64 output with line breaks.
*
* The default option (simdutf::base64_default) uses the characters `+` and `/`
* as part of its alphabet. Further, it adds padding (`=`) at the end of the
* output to ensure that the output length is a multiple of four.
*
* The URL option (simdutf::base64_url) uses the characters `-` and `_` as part
* of its alphabet. No padding is added at the end of the output.
*
* This function always succeeds.
*
* The default line length is default_line_length (76)
*
* @param input the binary to process
* @param length the length of the input in bytes
* @param output the pointer to a buffer that can hold the conversion
* result (should be at least base64_length_from_binary_with_lines(length, options, line_length) bytes long)
* @param line_length the length of lines, must be at least 4 (otherwise it is interpreted as 4),
* @param options the base64 options to use, can be base64_default or
* base64_url, is base64_default by default.
* @return number of written bytes, will be equal to
* base64_length_from_binary_with_lines(length, options)
*/
size_t binary_to_base64_with_lines(const char *input, size_t length, char *output,
size_t line_length = simdutf::default_line_length,
base64_options options = base64_default) noexcept;
/**
* Convert a base64 input to a binary output.
*
* This function follows the WHATWG forgiving-base64 format, which means that it will
* ignore any ASCII spaces in the input. You may provide a padded input (with one or two
* equal signs at the end) or an unpadded input (without any equal signs at the end).
*
* See https://infra.spec.whatwg.org/#forgiving-base64-decode
*
* This function will fail in case of invalid input. When last_chunk_options = loose,
* there are two possible reasons for failure: the input contains a number of
* base64 characters that when divided by 4, leaves a single remainder character
* (BASE64_INPUT_REMAINDER), or the input contains a character that is not a
* valid base64 character (INVALID_BASE64_CHARACTER).
*
* When the error is INVALID_BASE64_CHARACTER, r.count contains the index in the input
* where the invalid character was found. When the error is BASE64_INPUT_REMAINDER, then
* r.count contains the number of bytes decoded.
*
* You should call this function with a buffer that is at least maximal_binary_length_from_base64(input, length) bytes long.
* If you fail to provide that much space, the function may cause a buffer overflow.
*
* Advanced users may want to tailor how the last chunk is handled. By default,
* we use a loose (forgiving) approach but we also support a strict approach
* as well as a stop_before_partial approach, as per the following proposal:
*
* https://tc39.es/proposal-arraybuffer-base64/spec/#sec-frombase64
*
* @param input the base64 string to process, in ASCII stored as 16-bit units
* @param length the length of the string in 16-bit units
* @param output the pointer to a buffer that can hold the conversion result (should be at least maximal_binary_length_from_base64(input, length) bytes long).
* @param options the base64 options to use, can be base64_default or base64_url, is base64_default by default.
* @param last_chunk_options the last chunk handling options,
* last_chunk_handling_options::loose by default
* but can also be last_chunk_handling_options::strict or
* last_chunk_handling_options::stop_before_partial.
* @return a result pair struct (of type simdutf::result containing the two fields error and count) with an error code and either position of the INVALID_BASE64_CHARACTER error (in the input in units) if any, or the number of bytes written if successful.
*/
simdutf_warn_unused result base64_to_binary(const char16_t * input, size_t length, char* output, base64_options options = base64_default, last_chunk_handling_options last_chunk_options =
last_chunk_handling_options::loose) noexcept;
/**
* Convert a base64 input to a binary output.
*
* This function follows the WHATWG forgiving-base64 format, which means that it
* will ignore any ASCII spaces in the input. You may provide a padded input
* (with one or two equal signs at the end) or an unpadded input (without any
* equal signs at the end).
*
* See https://infra.spec.whatwg.org/#forgiving-base64-decode
*
* This function will fail in case of invalid input. When last_chunk_options =
* loose, there are three possible reasons for failure: the input contains a
* number of base64 characters that when divided by 4, leaves a single remainder
* character (BASE64_INPUT_REMAINDER), the input contains a character that is
* not a valid base64 character (INVALID_BASE64_CHARACTER), or the output buffer
* is too small (OUTPUT_BUFFER_TOO_SMALL).
*
* When OUTPUT_BUFFER_TOO_SMALL, we return both the number of bytes written
* and the number of units processed, see description of the parameters and
* returned value.
*
* When the error is INVALID_BASE64_CHARACTER, r.count contains the index in the
* input where the invalid character was found. When the error is
* BASE64_INPUT_REMAINDER, then r.count contains the number of bytes decoded.
*
* The default option (simdutf::base64_default) expects the characters `+` and
* `/` as part of its alphabet. The URL option (simdutf::base64_url) expects the
* characters `-` and `_` as part of its alphabet.
*
* The padding (`=`) is validated if present. There may be at most two padding
* characters at the end of the input. If there are any padding characters, the
* total number of characters (excluding spaces but including padding
* characters) must be divisible by four.
*
* The INVALID_BASE64_CHARACTER cases are considered fatal and you are expected
* to discard the output unless the parameter decode_up_to_bad_char is set to
* true. In that case, the function will decode up to the first invalid character.
* Extra padding characters ('=') are considered invalid characters.
*
* Advanced users may want to tailor how the last chunk is handled. By default,
* we use a loose (forgiving) approach but we also support a strict approach
* as well as a stop_before_partial approach, as per the following proposal:
*
* https://tc39.es/proposal-arraybuffer-base64/spec/#sec-frombase64
*
* @param input the base64 string to process, in ASCII stored as 8-bit
* or 16-bit units
* @param length the length of the string in 8-bit or 16-bit units.
* @param output the pointer to a buffer that can hold the conversion
* result.
* @param outlen the number of bytes that can be written in the output
* buffer. Upon return, it is modified to reflect how many bytes were written.
* @param options the base64 options to use, can be base64_default or
* base64_url, is base64_default by default.
* @param last_chunk_options the last chunk handling options,
* last_chunk_handling_options::loose by default
* but can also be last_chunk_handling_options::strict or
* last_chunk_handling_options::stop_before_partial.
* @param decode_up_to_bad_char if true, the function will decode up to the
* first invalid character. By default (false), it is assumed that the output
* buffer is to be discarded. When there are multiple errors in the input,
* using decode_up_to_bad_char might trigger a different error.
* @return a result pair struct (of type simdutf::result containing the two
* fields error and count) with an error code and position of the
* INVALID_BASE64_CHARACTER error (in the input in units) if any, or the number
* of units processed if successful.
*/
simdutf_warn_unused result base64_to_binary_safe(const char * input, size_t length, char* output, size_t& outlen, base64_options options = base64_default,
last_chunk_handling_options last_chunk_options = loose,
bool decode_up_to_bad_char = false) noexcept;
simdutf_warn_unused result base64_to_binary_safe(const char16_t * input, size_t length, char* output, size_t& outlen, base64_options options = base64_default,
last_chunk_handling_options last_chunk_options = loose,
bool decode_up_to_bad_char = false) noexcept;
```
Find
-----
The C++ standard library provides `std::find` for locating a character in a string, but its performance can be suboptimal on modern hardware. To address this, we introduce `simdutf::find`, a high-performance alternative optimized for recent processors using SIMD instructions. It operates on raw pointers (`char` or `char16_t`) for maximum efficiency.
```cpp
std::string input = "abc";
const char* result =
simdutf::find(input.data(), input.data() + input.size(), 'c');
// result should point at the letter 'c'
```
The `simdutf::find` interface is straightforward and efficient.
```cpp
/**
* Find the first occurrence of a character in a string. If the character is
* not found, return a pointer to the end of the string.
* @param start the start of the string
* @param end the end of the string
* @param character the character to find
* @return a pointer to the first occurrence of the character in the string,
* or a pointer to the end of the string if the character is not found.
*
*/
simdutf_warn_unused const char *find(const char *start, const char *end,
char character) noexcept;
simdutf_warn_unused const char16_t *find(const char16_t *start, const char16_t *end,
char16_t character) noexcept;
```
# C++20 and std::span usage in simdutf
If you are compiling with C++20 or later, span support is enabled. This allows you to use simdutf in a safer and more expressive way, without manually handling pointers and sizes.
The span interface is easy to use. If you have a container like `std::vector` or `std::array`, you can pass the container directly. If you have a pointer and a size, construct a `std::span` and pass it.
When dealing with ranges of bytes (like `char`), anything that has a `std::span-like` interface (has appropriate `data()` and `size()` member functions) is accepted. Ranges of larger types are accepted as `std::span` arguments.
## Example
Suppose you want to convert a UTF-16 string to UTF-8:
```cpp
#include <simdutf.h>
#include <vector>
#include <span>
#include <string>
std::u16string utf16_input = u"Bonjour le monde";
std::vector<char> utf8_output(64); // ensure sufficient size
// Use std::span for input and output
size_t written = simdutf::convert_utf16_to_utf8_safe(utf16_input, utf8_output);
```
## Note
- You are still responsible for providing a sufficiently large output buffer, just as with the pointer/size API.
The sutf command-line tool
------
We also provide a command-line tool which can be build as follows:
```
cmake -B build && cmake --build build --target sutf
```
This command builds the executable in `./build/tool/` under most platforms. The sutf tool enables the user to easily transcode files from one encoding to another directly from the command line.
The usage is similar to [iconv](https://www.gnu.org/software/libiconv/) (see `sutf --help` for more details). The sutf command-line tool relies on the simdutf library functions for fast transcoding of supported
formats (UTF-8, UTF-16LE, UTF-16BE and UTF-32). If iconv is found on the system and simdutf does not support a conversion, the sutf tool falls back on iconv: a message lets the user know if iconv is available
during compilation. The following is an example of transcoding two input files to an output file, from UTF-8 to UTF-16LE:
```
sutf -f UTF-8 -t UTF-16LE -o output_file.txt first_input_file.txt second_input_file.txt
```
Manual implementation selection
-------------------------------
When compiling the library for x64 processors, we build several implementations of each functions. At runtime, the best
implementation is picked automatically. Advanced users may want to pick a particular implementation, thus bypassing our
runtime detection. It is possible and even relatively convenient to do so. The following C++ program checks all the available
implementation, and selects one as the default:
```cpp
#include "simdutf.h"
#include <cstdlib>
#include <iostream>
#include <string>
int main() {
// This is just a demonstration, not actual testing required.
std::string source = "La vie est belle.";
std::string chosen_implementation;
for (auto &implementation : simdutf::get_available_implementations()) {
if (!implementation->supported_by_runtime_system()) {
continue;
}
bool validutf8 = implementation->validate_utf8(source.c_str(), source.size());
if (!validutf8) {
return EXIT_FAILURE;
}
std::cout << implementation->name() << ": " << implementation->description()
<< std::endl;
chosen_implementation = implementation->name();
}
auto my_implementation =
simdutf::get_available_implementations()[chosen_implementation];
if (!my_implementation) {
return EXIT_FAILURE;
}
if (!my_implementation->supported_by_runtime_system()) {
return EXIT_FAILURE;
}
simdutf::get_active_implementation() = my_implementation;
bool validutf8 = simdutf::validate_utf8(source.c_str(), source.size());
if (!validutf8) {
return EXIT_FAILURE;
}
if (simdutf::get_active_implementation()->name() != chosen_implementation) {
return EXIT_FAILURE;
}
std::cout << "I have manually selected: " << simdutf::get_active_implementation()->name() << std::endl;
return EXIT_SUCCESS;
}
```
Thread safety
-----------
We built simdutf with thread safety in mind. The simdutf library is single-threaded throughout.
The CPU detection, which runs the first time parsing is attempted and switches to the fastest parser for your CPU, is transparent and thread-safe. Our runtime dispatching is based on global objects that are instantiated at the beginning of the main thread and may be discarded at the end of the main thread. If you have multiple threads running and some threads use the library while the main thread is cleaning up resources, you may encounter issues. If you expect such problems, you may consider using [std::quick_exit](https://en.cppreference.com/w/cpp/utility/program/quick_exit).
References
-----------
* Robert Clausecker, Daniel Lemire, [Transcoding Unicode Characters with AVX-512 Instructions](https://arxiv.org/abs/2212.05098), Software: Practice and Experience 53 (12), 2023.
* Daniel Lemire, Wojciech Muła, [Transcoding Billions of Unicode Characters per Second with SIMD Instructions](https://arxiv.org/abs/2109.10433), Software: Practice and Experience 52 (2), 2022.
* John Keiser, Daniel Lemire, [Validating UTF-8 In Less Than One Instruction Per Byte](https://arxiv.org/abs/2010.03090), Software: Practice and Experience 51 (5), 2021.
* Wojciech Muła, Daniel Lemire, [Base64 encoding and decoding at almost the speed of a memory copy](https://arxiv.org/abs/1910.05109), Software: Practice and Experience 50 (2), 2020.
* Wojciech Muła, Daniel Lemire, [Faster Base64 Encoding and Decoding using AVX2 Instructions](https://arxiv.org/abs/1704.00605), ACM Transactions on the Web 12 (3), 2018.
Stars
-------
[](https://www.star-history.com/#simdutf/simdutf&Date)
License
-------
This code is made available under the [Apache License 2.0](https://www.apache.org/licenses/LICENSE-2.0.html) as well as the MIT license. As a user, you can pick the license you prefer.
We include a few competitive solutions under the benchmarks/competition directory. They are provided for
research purposes only.
|
